
Erlang 学习笔记
原文地址:http://hscarb.github.io/other/20220614-erlang-note.html
Erlang 学习笔记
顺序编程
基本概念
Erlang shell
# 启动
erl
# 停止
q() # 对应 init:stop()
# 立即停止系统
erlang:halt()
% 注释
可以挂接一个shell到集群里另一个Erlang节点上运行的Erlang系统,甚至还可以生成一个安全shell(secure shell,即ssh)直接连接远程计算机上运行的Erlang系统。通过它,可以与Erlang节点系统中任何节点上的任何程序进行交互。
f() 命令让shell忘记现有的任何绑定。help() 命令获取帮助。
6> help().
** shell internal commands **
b() -- display all variable bindings
e(N) -- repeat the expression in query <N>
f() -- forget all variable bindings
f(X) -- forget the binding of variable X
h() -- history
h(Mod) -- help about module
h(Mod,Func)-- help about function in module
h(Mod,Func,Arity) -- help about function with arity in module
ht(Mod) -- help about a module's types
ht(Mod,Type) -- help about type in module
ht(Mod,Type,Arity) -- help about type with arity in module
hcb(Mod) -- help about a module's callbacks
hcb(Mod,CB) -- help about callback in module
hcb(Mod,CB,Arity) -- help about callback with arity in module
history(N) -- set how many previous commands to keep
results(N) -- set how many previous command results to keep
catch_exception(B) -- how exceptions are handled
v(N) -- use the value of query <N>
rd(R,D) -- define a record
rf() -- remove all record information
rf(R) -- remove record information about R
rl() -- display all record information
rl(R) -- display record information about R
rp(Term) -- display Term using the shell's record information
rr(File) -- read record information from File (wildcards allowed)
rr(F,R) -- read selected record information from file(s)
rr(F,R,O) -- read selected record information with options
** commands in module c **
bt(Pid) -- stack backtrace for a process
c(Mod) -- compile and load module or file <Mod>
cd(Dir) -- change working directory
flush() -- flush any messages sent to the shell
help() -- help info
h(M) -- module documentation
h(M,F) -- module function documentation
h(M,F,A) -- module function arity documentation
i() -- information about the system
ni() -- information about the networked system
i(X,Y,Z) -- information about pid <X,Y,Z>
l(Module) -- load or reload module
lm() -- load all modified modules
lc([File]) -- compile a list of Erlang modules
ls() -- list files in the current directory
ls(Dir) -- list files in directory <Dir>
m() -- which modules are loaded
m(Mod) -- information about module <Mod>
mm() -- list all modified modules
memory() -- memory allocation information
memory(T) -- memory allocation information of type <T>
nc(File) -- compile and load code in <File> on all nodes
nl(Module) -- load module on all nodes
pid(X,Y,Z) -- convert X,Y,Z to a Pid
pwd() -- print working directory
q() -- quit - shorthand for init:stop()
regs() -- information about registered processes
nregs() -- information about all registered processes
uptime() -- print node uptime
xm(M) -- cross reference check a module
y(File) -- generate a Yecc parser
** commands in module i (interpreter interface) **
ih() -- print help for the i module
true
整数运算
1> 2 + 3 * 4.
14
Erlang可以用任意长度的整数执行整数运算。在Erlang里,整数运算是精确的,因此无需担心运算溢出或无法用特定字长( word size)来表示某个整数。
变量
1> X = 123.
2> X.
123
- 所有变量名都必须以大写字母开头。
- Erlang 中的
=是一个模式匹配操作符,当关联一个值与一个变量时,所下的是一种断言,也就是事实陈述。这个变量具有那个值,仅此而已。 - X 不是一个变量,是一次性赋值变量,只能被赋值一次。
- 变量的作用域是它定义时所处的语汇单元。不存在全局变量或私有变量的说法。
在Erlang里, =是一次模式匹配操作。 Lhs = Rhs 的真正意思是:计算右侧( Rhs)的值,然后将结果与左侧( Lhs)的模式相匹配。
我们第一次说 X = SomeExpression时, Erlang对自己说:“我要做些什么才能让这条语句为真?”因为X还没有值,它可以绑定X到SomeExpression这个值上,这条语句就成立了。
这符合了 Erlang 这种函数式编程语言的不可变状态。
浮点数
1> 5/3.
1.6666666666666667 % 用 / 给两个整数做除法时,结果会自动转换成浮点数。
2> 4/2.
2.0 % 整除结果仍是浮点数
3> 5 div 3.
1 % N 除以 M 然后舍去余数
4> 5 rem 3.
2 % N 除以 M 后剩下的余数
5> 4 div 2.
2
% 浮点数的程序会存在和C等语言一样的浮点数取整与精度问题
原子
- 表示常量值,也可以视作枚举类型。
- 原子是全局性的,而且不需要宏定义或包含文件就能实现。
- 原子以小写字母开头,后接一串字母、数字、下划线(_)或at(@)符号。
- 也可以放在单引号内,以大写字母开头或包含字母数字以外字符的原子。
- 原子的值就是它本身
元组
- 数量固定的项目归组成单一的实体
- 元组里的字段没有名字,常用做法是将元组第一个元素设为一个原子,用来表示元组是什么。
{point, 10, 5}.
Person = {person, {name, joe}, {height, 1.82}, {footsize, 42}, {eyecolour, brown}}.
% 用模式匹配的方式提取元组的值
Point = {point, 10, 45}.
{point, X, Y} = Point.
% 用_作为占位符
Person = {person, {name, joe, armstrong}, {footsize, 42}}.
{_,{_,Who,_},_}=Person.
Who.
> joe
列表
[8,hello,0,{cost,apple,10},3]
- 用来存放任意数量的事物
- 第一个元素称为列表头,剩下元素是列表尾。
- 访问列表头是一种非常高效的操作,因此基本上所有的列表处理函数都从提取列表头开始,然后对它做一些操作,接着处理列表尾。
- 如果T是一个列表,那么[H|T]也是一个列表, 它的头是H,尾是T。竖线(|) 把列表的头与尾分隔开。 []是一个空列表。
% 扩展列表
7> Things = [{apples,10},{pears,6},{milk,3}].
[{apples,10},{pears,6},{milk,3}]
8> Things1=[{oranges,4},{newspaper,1}|Things].
[{oranges,4},{newspaper,1},{apples,10},{pears,6},{milk,3}]
% 提取列表元素,[X|Y] = L( X和Y都是未绑定变量)会提取列表头作为X,列表尾作为Y。
9> [Buy1|Things2]=Things1.
[{oranges,4},{newspaper,1},{apples,10},{pears,6},{milk,3}]
10> Buy1.
{oranges,4}
11> Things2.
[{newspaper,1},{apples,10},{pears,6},{milk,3}]
%%
12> [Buy2,Buy3|Things3]=Things2.
[{newspaper,1},{apples,10},{pears,6},{milk,3}]
13> Buy2.
{newspaper,1}
14> Buy3.
{apples,10}
15> Things3.
[{pears,6},{milk,3}]
字符串
严格来说,Erlang 里没有字符串。用整数组成的列表或一个二进制型表示字符串。当用整数列表表示字符串时,列表里的每个元素代表了一个Unicode字符。
16> Name="Hello". % "Hello"其实只是一个列表的简写,这个列表包含了代表字符串里各个字符的整数字符代码
"Hello"
% shell打印某个列表的值时,如果列表内的所有整数都代表可打印字符,它就会将其打印成字符串字面量。否则,打印成列表记法
17> [1,2,3].
[1,2,3]
18> [83,117,114,112,114,105,115,101].
"Surprise"
19> [1,83,117,114,112,114,105,115,101].
[1,83,117,114,112,114,105,115,101]
% 如果shell将某个整数列表打印成字符串,而你其实想让它打印成一列整数,那就必须使用格式化的写语句
1> X = [97,98,99].
"abc"
3> io:format("~w~n",[X]).
[97,98,99]
% $a实际上就是代表字符a的整数
20> I = $s.
115
22> [$S,117,114,112,114,105,115,101].
"Surprise"
% 必须使用特殊的语法才能输入某些字符,在打印列表时也要选择正确的格式惯例。
23> X="a\x{221e}b".
[97,8734,98]
24> io:format("~ts~n",[X]).
a\x{221E}b
模块与函数
模块:module
模块是Erlang的基本代码单元。模块保存在扩展名为 .erl 的文件里,而且必须先编译才能运行模块里的代码。编译后的模块以 .beam 作为扩展名。
- 逗号
,分隔函数调用、数据构造和模式中的参数。 - 分号
;分隔子句。我们能在很多地方看到子句,例如函数定义,以及case、 if、try..catch和receive表达式。 - 句号
.(后接空白)分隔函数整体,以及shell里的表达式。
% geometry.erl
-module(geometry). % 模块声明,模块名必须与存放该模块的主文件名相同
-export([area/1]). % 导出声明,Name/N 指带有 N 个参数的函数 Name。已导出函数相当于公共方法,未导出函数相当于私有方法
% 函数定义,area 函数有两个子句
area({rectangle, Width, Height}) -> Width * Height; % 子句以分号隔开
area({square, Side}) -> Side * Side. % 以句号结尾
1> c(geometry). % 在 erlang shell 中编译,编译之后产生 geometry.beam 目标代码块
{ok,geometry}
2> geometry:area({rectangle, 10, 5}). % 调用函数,要附上模块名
50
3> geometry:area({square, 3}).
9
-module(geometry).
-export([area/1, test/0]).
% 添加测试,测试仅仅需要模式匹配和=
test() ->
12 = area({rectangle, 3, 4}),
144 = area({square, 12}),
tests_worked.
area({rectangle, Width, Height}) ->
Width * Height;
area({square, Side}) ->
Side * Side.
5> c(geometry).
{ok,geometry}
6> geometry:test().
tests_worked
% 情况分析函数
total([{What, N} | T]) -> shop:cost(What) * N + total(T);
total([]) -> 0.
高阶函数 fun
- Erlang 是函数式编程语言,表示函数可以被用作参数,也可以返回函数。
- 操作其他函数的函数被称为高阶函数。
- 代表函数的数据类型是
fun。
1> Double = fun(X) -> 2 * X end.
#Fun<erl_eval.44.65746770>
2> Double(2).
4
% fun 可以有多个子句
3> TempConvert = fun({c, C}) -> {f, 32 + C * 9 / 5};
({f, F}) -> {c, (F - 32) * 5 / 9}
end.
#Fun<erl_eval.44.65746770>
4> TempConvert({c, 100}).
{f,212.0}
5> TempConvert({f, 212}).
{c,100.0}
% 标准库高阶函数
%% map
6> L = [1,2,3,4].
[1,2,3,4]
7> lists:map(fun(X) -> 2 * X end, L).
[2,4,6,8]
%% filter
8> Even = fun(X) -> (X rem 2) =:= 0 end.
#Fun<erl_eval.44.65746770>
9> Even(8).
true
10> Even(7).
false
11> lists:map(Even, [1,2,3,4,5,6,7,8]).
[false,true,false,true,false,true,false,true]
12> lists:filter(Even, [1,2,3,4,5,6,7,8]).
[2,4,6,8]
% 返回 fun 的函数,括号内的东西就是返回值
13> MakeTest = fun(L) -> (fun(X) -> lists:member(X, L) end) end.
#Fun<erl_eval.44.65746770>
15> Fruit = [apple, pear, orange].
[apple,pear,orange]
16> IsFruit = MakeTest(Fruit).
#Fun<erl_eval.44.65746770>
17> IsFruit(pear).
true
18> IsFruit(dog).
false
19> lists:filter(IsFruit, [dog,orange,cat,apple,bear]).
[orange,apple]
22> Mult = fun(Times) -> (fun(X) -> X * Times end) end.
#Fun<erl_eval.44.65746770>
23> Triple = Mult(3).
#Fun<erl_eval.44.65746770>
24> Triple(5).
15
实现 for
% Erlang 没有 for 循环,而是需要自己编写控制结构
% 创建列表[F(1), F(2), ..., F(10)]
for(Max, Max, F) -> [F(Max)];
for(I, Max, F) -> [F(I) | for(I + 1, Max, F)].
9> lib_misc:for(1,10,fun(I)->I end).
[1,2,3,4,5,6,7,8,9,10]
10> lib_misc:for(1,10,fun(I)->I*I end).
[1,4,9,16,25,36,49,64,81,100]
列表处理(sum、map)
%% 列表求和函数
sum([H | T]) -> H + sum(T);
sum([]) -> 0.
%% map 函数
map(_, []) -> [];
map(F, [H | T]) -> [F(H) | map(F, T)].
total(L) -> sum(map(fun({What, N}) -> shop:cost(What) * N end, L)).
列表推导([F(X) || X <- L])
列表推导(list comprehension)是无需使用fun、 map或filter就能创建列表的表达式。它让程序变得更短,更容易理解。
1> L = [1,2,3,4,5].
[1,2,3,4,5]
2> [2*X||X<-L]. % [F(X) || X <- L]:由 F(X) 组成的列表(X 从列表 L 中提取)
[2,4,6,8,10]
列表推导的常规形式
[X || Qualifier1, Qualifier2, ...]
X 是任一表达式,后面的限定符可以是生成器、位串生成器或过滤器。
- 生成器(generator)的写法是
Pattern <- ListExpr,其中的ListExp必须是一个能够得出列表的表达式。 - 位串(bitstring)生成器的写法是
BitStringPattern <= BitStringExpr,其中的BitStringExpr必须是一个能够得出位串的表达式。 - 过滤器(filter)既可以是判断函数(即返回true或false的函数),也可以是布尔表达式。请注意,列表推导里的生成器部分起着过滤器的作用
%% 快速排序
qsort([]) -> [];
qsort([Pivot | T]) ->
qsort([X || X <- T, X < Pivot]) % 生成器 + 过滤器,生成一个比 Pivot 小的数组成的列表,递归
++ [Pivot] % ++ 是中缀插入操作符,在中间插入 Pivot
++ qsort([X || X <- T, X >= Pivot]).
%% 毕达哥拉斯三元数组
%% 提取1到N的所有A值,1到N的所有B值,1到N的所有C值,条件是A + B + C小于等于N并且A*A + B*B = C*C。
pythag(N) ->
[
{A, B, C} ||
A <- lists:seq(1, N),
B <- lists:seq(1, N),
C <- lists:seq(1, N),
A + B + C =< N,
A * A + B * B =:= C * C
].
内置函数
built-in function,是那些作为Erlang语言定义一部分的函数。有些内置函数是用Erlang实现的,但大多数是用Erlang虚拟机里的底层操作实现的。最常用的内置函数(例如list_to_tuple)是自动导入的。
4> list_to_tuple([12,cat,"hello"]).
{12,cat,"hello"}
5> time().
{22,55,25}
关卡(when)
- 关卡(guard)是一种结构,可以用它来增加模式匹配的威力,它通过
when引入。通过使用关卡,可以对某个模式里的变量执行简单的测试和比较。- 关卡由一系列关卡表达式组成,由
,分割,都为 true 是值才为 true。(AND)
- 关卡由一系列关卡表达式组成,由
- 关卡序列(guard sequence)是指单一或一系列的关卡,用
;分割,只要一个为 true,它的值就为 true。(OR) - 原子 true 关卡防止在某个 if 表达式的最后。
% Guard 是用于增强模式匹配的结构。
% Guard 可用于简单的测试和比较。
% Guard 可用于函数定义的头部,以`when`关键字开头,或者其他可以使用表达式的地方。
max(X, Y) when X > Y -> X;
max(X, Y) -> Y.
% guard 可以由一系列 guard 表达式组成,这些表达式以逗号分隔。
% `GuardExpr1, GuardExpr2, ..., GuardExprN` 为真,当且仅当每个 guard 表达式均为真。
is_cat(A) when is_atom(A), A =:= cat -> true;
is_cat(A) -> false.
is_dog(A) when is_atom(A), A =:= dog -> true;
is_dog(A) -> false.
% guard 序列 `G1; G2; ...; Gn` 为真,当且仅当其中任意一个 guard 表达式为真。
is_pet(A) when is_dog(A); is_cat(A) -> true;
is_pet(A) -> false.
case 表达式
case Expression of
Pattern1 [when Guard1] -> Body1;
Pattern2 [when Guard2] -> Body2;
...
end
% `case` 表达式。
% `filter` 返回由列表`L`中所有满足`P(x)`为真的元素`X`组成的列表。
filter(P, [H|T]) ->
case P(H) of
true -> [H|filter(P, T)];
false -> filter(P, T)
end;
filter(P, []) -> [].
filter(fun(X) -> X rem 2 == 0 end, [1, 2, 3, 4]). % [2, 4]
Expression被执行,假设它的值为ValueValue轮流与Pattern1(带有可选的关卡Guard1)、Pattern2等模式进行匹配,直到匹配成功。- 一旦发现匹配,相应的表达式序列就会执行,而表达式序列执行的结果就是
case表达式的值。如果所有模式都不匹配,就会发生异常错误(exception)。
if 表达式
if
Guard1 -> Expr_seq1;
Guard2 -> Expr_seq2;
...
end
% `if` 表达式。
max(X, Y) ->
if
X > Y -> X;
X < Y -> Y;
true -> nil;
end.
- 执行
Guard1。 如果得到的值为true,那么if的值就是执行表达式序列Expr_seq1所得到的值。 - 如果
Guard1不成功,就会执行Guard2, 以此类推,直到某个关卡成功为止。 - if表达式必须至少有一个关卡的执行结果为true, 否则就会发生异常错误。
- 很多时候,
if表达式的最后一个关卡是原子true, 确保当其他关卡都失败时表达式的最后部分会被执行。(相当于最后带 else)因为 erlang 的所有表达式都应该有值。
归集器
只遍历列表一次,返回两个列表。
%% 归集器
odds_and_even(L) -> odds_and_evens_acc(L, [], []).
odds_and_evens_acc([H|T], Odds, Evens) ->
case (H rem 2) of
1 -> odds_and_evens_acc(T, [H|Odds], Evens);
0 -> odds_and_evens_acc(T, Odds, [H|Evens])
end;
odds_and_evens_acc([], Odds, Evens) ->
{Odds, Evens}.
记录(record)与映射组(map)
元组用于保存固定数量的元素,而列表用于保存可变数量的元素。记录其实就是元组的另一种形式。
- 使用 record:有一大堆元组,并且每个元组都有相同的结构
- 使用 map:键值对
record
% Record 可以将元组中的元素绑定到特定的名称。
% Record 定义可以包含在 Erlang 源代码中,也可以放在后缀为`.hrl`的文件中(Erlang 源代码中 include 这些文件)。
-record(todo, {
status = reminder, % Default value
who = joe,
text
}).
% 在定义某个 record 之前,我们需要在 shell 中导入 record 的定义。
% 我们可以使用 shell 函数`rr` (read records 的简称)。
rr("records.hrl"). % [todo]
% 创建和更新 record。
X = #todo{}. % 创建 todo,所有键都是原子
% #todo{status = reminder, who = joe, text = undefined}
X1 = #todo{status = urgent, text = "Fix errata in book"}.
% #todo{status = urgent, who = joe, text = "Fix errata in book"}
X2 = X1#todo{status = done}. % 创建 X1 的副本,并修改 status 为 done
% #todo{status = done,who = joe,text = "Fix errata in book"}
% 提取 record 字段
> #todo{who=W, text=Txt} = X2.
> W.
joe
> Txt.
"Fix errata in book"
% 如果只是想要记录里的单个字段,就可以使用“点语法”来提取该字段。
> X2#todo.text.
"Fix errata in book"
% 让 shell 忘掉 todo 定义
rf(todo).
map
- 映射组在系统内部是作为有序集合存储的,打印时总是使用各键排序后的顺序。
- 表达式K => V有两种用途,一种是将现有键K的值更新为新值V,另一种是给映射组添加一个全新的K-V对。这个操作总是成功的。
- 表达式K := V的作用是将现有键K的值更新为新值V。 如果被更新的映射组不包含键K,这个操作就会失败。
- 映射组在比较时首先会比大小,然后再按照键的排序比较键和值。
% 创建 map
> F1 = #{a => 1, b => 2}.
#{a => 1,b => 2}
% => 更新或设值
11> F3 = F1#{c=>xx}.
#{a => 1,b => 2,c => xx}
% := 只能更新值
12> F4=F1#{c := 3}.
** exception error: bad key: c
in function maps:update/3
called as maps:update(c,3,#{a => 1,b => 2})
*** argument 3: not a map
in call from erl_eval:'-expr/5-fun-0-'/2 (erl_eval.erl, line 256)
in call from lists:foldl/3 (lists.erl, line 1267)
13> F4 = F3#{c := 3}.
#{a => 1,b => 2,c => 3}



顺序程序的错误处理
- exit(Why)
- 当你确实想要终止当前进程时就用它。如果这个异常错误没有被捕捉到,信号
{'EXIT', Pid,Why}就会被广播给当前进程链接的所有进程。
- 当你确实想要终止当前进程时就用它。如果这个异常错误没有被捕捉到,信号
- throw(Why)
- 这个函数的作用是抛出一个调用者可能想要捕捉的异常错误。在这种情况下,我们注明了
被调用函数可能会抛出这个异常错误。有两种方法可以代替它使用- 为通常的情形编写代码并且有意忽略异常错误
- 把调用封装在一个
try...catch表达式里, 然后对错误进行处理。
- 这个函数的作用是抛出一个调用者可能想要捕捉的异常错误。在这种情况下,我们注明了
- error(Why)
- 这个函数的作用是指示“崩溃性错误”,也就是调用者没有准备好处理的非常严重的问题。它与系统内部生成的错误差不多。
% 当遇到内部错误或显式调用时,会触发异常。
% 显式调用包括 `throw(Exception)`, `exit(Exception)` 和
% `erlang:error(Exception)`.
generate_exception(1) -> a;
generate_exception(2) -> throw(a);
generate_exception(3) -> exit(a);
generate_exception(4) -> {'EXIT', a};
generate_exception(5) -> erlang:error(a).
% Erlang 有两种捕获异常的方法。其一是将调用包裹在`try...catch`表达式中。
catcher(N) ->
try generate_exception(N) of
Val -> {N, normal, Val}
catch
throw:X -> {N, caught, thrown, X};
exit:X -> {N, caught, exited, X};
error:X -> {N, caught, error, X}
end.
% 另一种方式是将调用包裹在`catch`表达式中。
% 此时异常会被转化为一个描述错误的元组。
catcher(N) -> catch generate_exception(N).
用 try ... catch 捕获异常

try ... catch具有一个值try ... catch表达式和case表达式之间的相似性,像是它的强化版,基本上是case表达式加上最后的catch和after区块。
首先执行 FuncOrExpessionSeq 。 如果执行过程没有抛出异常错误,那么函数的返回值就会与Pattern1( 以及可选的关卡Guard1)、 Pattern2等模式进行匹配,直到匹配成功。如果能匹配,那么整个 try...catch 的值就通过执行匹配模式之后的表达式序列得出。
如果 FuncOrExpressionSeq 在执行中抛出了异常错误,那么ExPattern1等捕捉模式就会与它进行匹配,找出应该执行哪一段表达式序列。ExceptionType是一个原子( throw、exit和error其中之一),告诉我们异常错误是如何生成的。如果省略了ExceptionType, 就会使用默认值throw。
% Erlang 有两种捕获异常的方法。其一是将调用包裹在`try...catch`表达式中。
catcher(N) ->
try generate_exception(N) of
Val -> {N, normal, Val}
catch
throw:X -> {N, caught, thrown, X};
exit:X -> {N, caught, exited, X};
error:X -> {N, caught, error, X}
end.
demo1() ->
[catcher(I) || I <- [1, 2, 3, 4, 5]].
% 提供了概括信息
>try_test:demo1().
[{1,normal,a},
{2,caught,thrown,a},
{3,caught,exited,a},
{4,normal,{'EXIT',a}},
{5,caught,error,a}]
用 catch 捕捉异常错误
catch 和 try ... catch 里的 catch 不是一回事,异常错误如果发生在 catch 语句里, 就会被转换成一个描述此错误的 {'EXIT', ...} 元组。
% 另一种方式是将调用包裹在`catch`表达式中。
% 此时异常会被转化为一个描述错误的元组。
catcher2(N) ->
catch generate_exception(N).
demo2() ->
[{I, catcher2(I)} || I <- [1, 2, 3, 4, 5]].
% 提供了详细的栈跟踪信息
> try_test:demo2().
[{1,a},
{2,a},
{3,{'EXIT',a}},
{4,{'EXIT',a}},
{5,
{'EXIT',{a,[{try_test,generate_exception,1,
[{file,"try_test.erl"},{line,23}]},
{try_test,catcher2,1,[{file,"try_test.erl"},{line,38}]},
{try_test,'-demo2/0-lc$^0/1-0-',1,
[{file,"try_test.erl"},{line,41}]},
{try_test,'-demo2/0-lc$^0/1-0-',1,
[{file,"try_test.erl"},{line,41}]},
{erl_eval,do_apply,6,[{file,"erl_eval.erl"},{line,689}]},
{shell,exprs,7,[{file,"shell.erl"},{line,686}]},
{shell,eval_exprs,7,[{file,"shell.erl"},{line,642}]},
{shell,eval_loop,3,[{file,"shell.erl"},{line,627}]}]}}}]
针对异常的编程样式
sqrt(X) when X < 0 ->
% 内置函数 error 可以改进错误信息
error({squareRootNegativeArgument, X});
sqrt(X) ->
math:sqrt(X).
% 函数多半应该返回 {ok, Value} 或 {error, Reason}
error_process(X) ->
case f(X) of
{ok, Val} ->
do_some_thing_with(Val);
{error, Why} ->
%% process this error
do_other_thing_with(error)
end.
% 捕捉一切可能的异常错误
error_process3(X) ->
try my_func(X)
catch
_:_ -> process_error()
end.
栈跟踪(erlang:get_stacktrace())
二进制型与位语法
顺序编程补遗
apply
内置函数apply(Mod, Func, [Arg1, Arg2, ..., ArgN])会将模块Mod里的Func函数应用到Arg1, Arg2, ... ArgN这些参数上。
> apply(erlang, atom_to_list, [hello]).
"hello"
应当尽量避免使用apply。 当函数的参数数量能预先知道时, M:F(Arg1, Arg2, ... ArgN) 这种调用形式要比apply好得多。
算数表达式

属性
模块属性的语法是 -AtomTag(...) , 它们被用来定义文件的某些属性。
包含预定义的模块属性和用户定义的属性。
预定义模块属性
-module(modulename):模块声明-import(Mod, [Name/Arity1, Name2/Arity2, ...]):列举了哪些函数要导入到模块中-compile(Options):添加 Options 到编译器选项列表中-vsn(Version):指定模块的版本号
用户定义的模块属性
-SomeTag(Value).:SomeTag必须是一个原子,Value 必须是一个字面数据类型
-author({jeo, armstring}).
-purpose("example of attributes").
块表达式
用于以下情形:代码某处的Erlang语法要求单个表达式,但我们想使用一个表达式序列
begin
Expr1,
...,
ExprN
end
布尔值 布尔表达式
Erlang没有单独的布尔值类型。不过原子true和false具有特殊的含义,可以用来表示布尔值。
not B1B1 and B2B1 or B2B1 xor B2
动态代码载入
每当调用 someModule:someFunction(...) 时,调用的总是最新版模块里的最新版函数,哪怕当代码在模块里运行时重新编译了该模块也是如此。
Erlang允许一个模块的两个版本同时运行:当前版和旧版。重新编译某个模块时,任何运行旧版代码的进程都会被终止,当前版成为旧版,新编译的版本则成为当前版
预处理器
Erlang模块在编译前会自动由Erlang的预处理器进行处理。预处理器会展开源文件里所有的宏,并插入必要的包含文件。
如调试某个有问题的宏时,应该保存预处理器的输出。
erlc -P some_module.erl
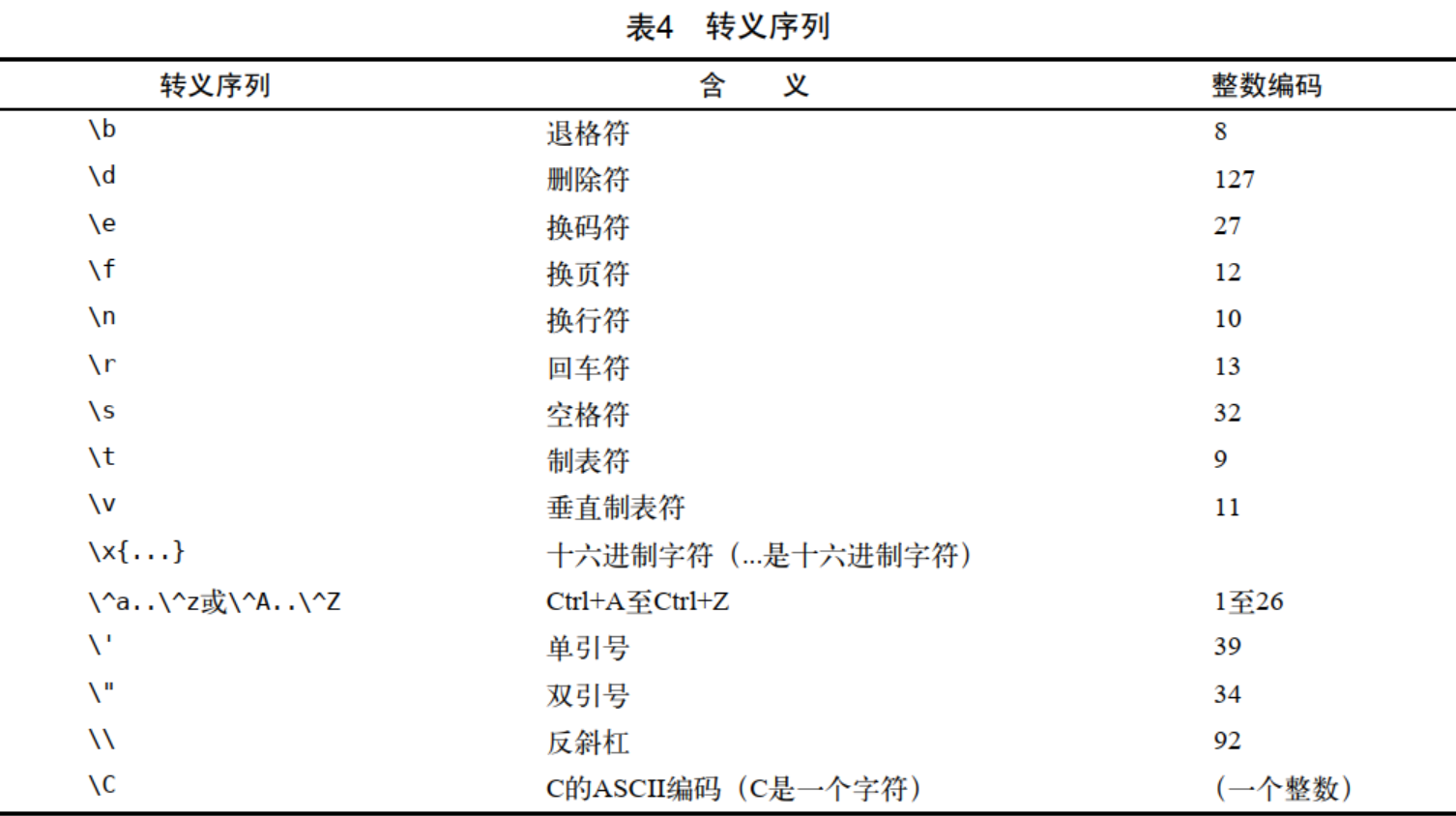
转义序列
可以在字符串和带引号的原子里使用转义序列来输入任何不可打印的字符。
函数引用
引用在当前或外部模块里定义的某个函数。
fun LocalFunc/Arity:引用当前模块的本地函数fun Mod:RemoteFunc/Arity:引用 Mod 模块的外部函数
包含文件
许多模块需要共享通用的记录定义,就会把它们放到包含文件里,再由所有需要这些定义的模块包含此文件
-include(Filename).
按照Erlang的惯例,包含文件的扩展名是.hrl。 FileName应当包含一个绝对或相对路径,使预处理器能找到正确的文件。包含库的头文件( library header file)时可以用下面的语法:
-include_lib("kernel/include/file.hrl")
列表操作:++、--
++ 和 -- 是用于列表添加和移除的中缀操作符。
A ++ B使A和B相加(也就是附加)。A -- B从列表A中移除列表B。 移除的意思是B中所有元素都会从A里面去除。- 请注意:如果符号X在B里只出现了K次,那么A只会移除前K个X。
宏 -define()
% 宏语法模板,erlang预处理器 epp 碰到 ?MacronName 的表达式时会展开这个宏
-define(Constant, Replacement).
-define(Func(Var1, Var2, .., Var), Replacement).
-define(macro1(X, Y), {a, X, Y}).
foo(A) ->
?macro1(A+10, b)
% --- 展开后 ---
foo(A) ->
{a, A+10, b}.
预制宏
?FILE?MODULE?LINE
宏控制流
-undef(Macro).-ifdef(Macro).-ifndef(Macro).-else.-endif.
数字
Erlang里的数字不是整数就是浮点数,整数的运算时精确的。
% K 进制
2#00101010
16#af6bfa23
% $ 写法,代表 ASCII 字符的整数代码
$a % 97的简写
% 浮点数
1.0
3.14159
-2.3e+6
23.56E-27
操作符优先级

进程字典
每个Erlang进程都有一个被称为进程字典( process dictionary)的私有数据存储区域。他是一个 map。
put(Key, Value) -> OldValue.get(Key) -> Value.get() -> [{Key, Value}].:返回整个进程字典get_keys(Value) -> [Key].:返回字典里面所有值为 Value 的键erase(Key) -> Value.erase() -> [{Key, Value}].
1> erase().
[]
2> put(x, 20).
undefined
3> get(x).
20
4> get(y).
undefined
5> put(y, 40).
undefined
6> get(y).
40
7> get().
[{y,40},{x,20}]
8> erase(x).
20
9> get().
[{y,40}]
引用
引用( reference)是一种全局唯一的Erlang数据类型。它们由内置函数 erlang:make_ref() 创建。 引用的用途是创建独一无二的标签,把它存放在数据里并在后面用于比较是否相等。
短路布尔表达式
只在必要时才对参数求值
Expr1 orelse Expr2:Expr1 || Expr2Expr1 andalso Expr2:Expr1 && Expr2
比较数据类型

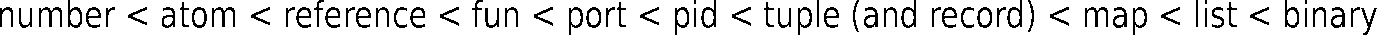
类型
编译和运行程序
改变开发环境
code:get_path()获取当前载入路径值-spec code:add_patha(Dir)向载入路径的开头添加一个新目录 Dir-spec code:add_pathz(Dir)向载入路径的末端添加一个新目录 Dir
运行程序的不同方式
% erlang shell
erl
1> c(hello).
{ok,hello}
2> hello:start().
Hello world
ok
% 命令行界面直接编译和运行
$ erlc hello.erl
% -noshell 不带交互式 shell 的方式启动 Erlang
% -s hello start 运行 hello:start() 函数
% -s init stop 在之前的命令完成后执行 init:stop() 函数,从而停止系统
$ erl -noshell -s hello start -s init stop
Hello world
#!/usr/bin/env escript
main(Args) ->
io:format("Hello world~n").
makefile 使编译自动化
并发和分布式程序
现实世界中的并发
Erlang进程没有共享内存,每个进程都有它自己的内存。要改变其他某个进程的内存,必须向它发送一个消息,并祈祷它能收到并理解这个消息。
并发编程
Erlang 编写并发程序只需要三个基本函数
基本并发函数
Pid = spawn(Mod, Func, Args):创建一个并行进程来执行apply(Mod, Func, Args)Pid = spawn(Fun):创建一个新的并发进程来执行FUn()Pid ! Message:向 Pid 进程发送消息 Message,消息发送是异步的。Pid1 ! Pid2 ! ... ! Msg意思是把消息Msg发给所有进程receive ... end:接收发送给某个进程的消息receive Pattern1 [when Guard1] -> Expressions1; Pattern2 [when Guard2] -> Expressions2; ... end
每个进程都带有一个进程邮箱,与进程同步创建。收到的消息会被放入该进程的邮箱,程序执行一条接收语句时才会读取邮箱。
客户端-服务器
% Erlang 依赖于 actor并发模型。在 Erlang 编写并发程序的三要素:
% 创建进程,发送消息,接收消息
% 启动一个新的进程使用`spawn`函数,接收一个函数作为参数
F = fun() -> 2 + 2 end. % #Fun<erl_eval.20.67289768>
spawn(F). % <0.44.0>
% `spawn` 函数返回一个pid(进程标识符),你可以使用pid向进程发送消息。
% 使用 `!` 操作符发送消息。
% 我们需要在进程内接收消息,要用到 `receive` 机制。
-module(caculateGeometry).
-compile(export_all).
caculateAera() ->
receive
{rectangle, W, H} ->
W * H;
{circle, R} ->
3.14 * R * R;
_ ->
io:format("We can only caculate area of rectangles or circles.")
end.
% 编译这个模块,在 shell 中创建一个进程,并执行 `caculateArea` 函数。
c(caculateGeometry).
CaculateAera = spawn(caculateGeometry, caculateAera, []).
CaculateAera ! {circle, 2}. % 12.56000000000000049738
% shell也是一个进程(process), 你可以使用`self`获取当前 pid
self(). % <0.41.0>
进程很轻巧
% 查看允许的最大进程数量
> erlang:system_info(processlimit).
262144
带超时的接收
为避免接收语句因为消息不来而一直等待,可以给接收语句增加一个超时设置,设置进程等待接收消息的最长时间。
receive
Pattern1 [when Guard1] ->
Expressions1;
Pattern2 [when Guard2] ->
Expressions2;
...
after Time ->
Expressions
end
选择性接收
receive 基本函数从进程邮箱中提取消息,做模式匹配,把未匹配的消息加入队列供以后处理,并管理超时。
注册进程
一般创建进程时,只有父进程知道子进程的 PID。使用注册进程的方法,可以公布进程标识符,让任何进程都能与该进程通信。
% 用 AnAtom 作为名称来注册进程 Pid
register(AnAtom, Pid)
% 移除与 AnAtom 关联的所有注册信息
unregister(AnAtom)
% 检查 AnAtom 是否已被注册
whereis(AnAtom) -> Pid | undefined
% 返回包含系统里所有注册进程的列表
registered() -> [AnAtom::atom()]
尾递归的说明
尾递归:收到消息进行处理之后立即再次调用 loop()
% 并发程序模板
% 接收并打印出任何发给它的消息
-module(ctemplate).
-compile(export_all).
start() ->
spawn(?MODULE, loop, []).
rpc(Pid, Request) ->
Pid ! {self(), Request},
receive
{Pid, Response} ->
Response
end.
loop(X) ->
receive
Any ->
io:format("Received:~p~n", [Any]),
loop(X)
end.
分布式编程
两种分布式模型
分布式 Erlang
程序在 Erlang 节点(node)上运行,节点是一个独立的 Erlang 系统,包含一个自带地址空间和进程组的完整虚拟机。
通常运行在数据同一个局域网的集群上,并受防火墙保护。
基于套接字的分布式模型
用 TCP/IP 套接字来编写运行在不可信环境中的分布式应用程序。不如分布式 Erlang 那样强大,但是更安全。
编写一个分布式程序
分布式应用程序编写顺序
- 在常规非分布式会话里编写和测试程序
- 在运行于同一台计算机上的两个不同 Erlang 节点中测试程序
- 在运行于两台物理隔离计算机上的两个不同 Erlang 节点里测试程序。
编程库与框架
接口技术
Erlang 如何与外部程序通信
Erlang 通过端口对象与外部程序通信。端口的行为就像一个 Erlang 进程。
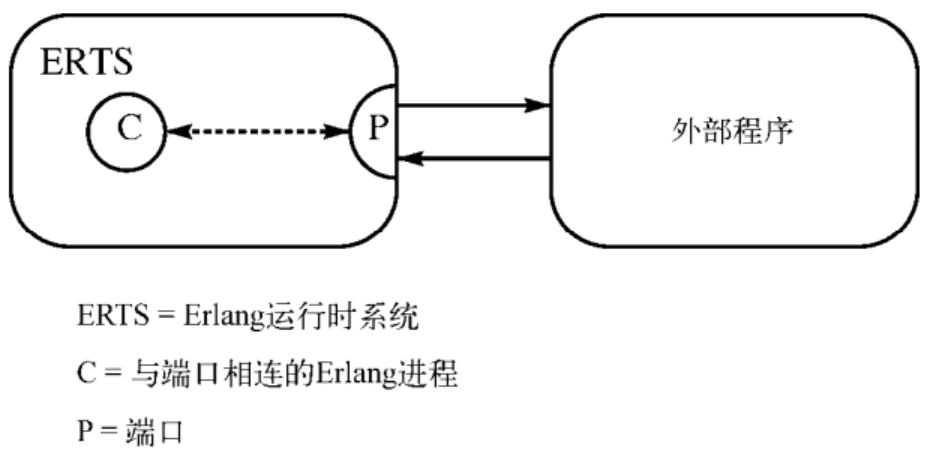
-spec open_port(PortName, [Opt]) -> Port 可以创建端口
% 向端口发送Data
Port ! {PicC, {command, Data}}
% 把相连进程的 PID 从 PicC 改为 Pid1
Port ! {PicC, {connect, Pid1}}
% 关闭端口
Port ! {Pid, close}
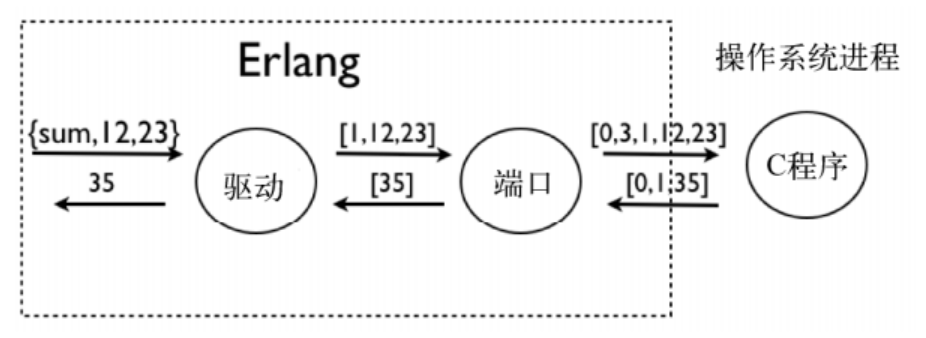
用端口建立外部 C 程序接口
在 Erlang 里调用 shell 脚本
% 运行字符串的命令并捕捉结果
os:cmd("ifconfig").
文件编程
套接字编程
用 WebSocket 和 Erlang 进行浏览
用 ETS 和 DETS 存储数据
ets 和 dets 是两个系统模块,用来高效存储海量的 Erlang 数据。它们都提供大型的键-值查询表。可以被多个进程共享。
- ETS(Erlang Term Storage):常驻内存,查找时间是恒定的。易失。没有垃圾收集机制,不会有垃圾收集的负担。
- DETS(Disk ETS):使用磁盘存储,速度慢于 ETS,内存占用也小很多。非易失。打开时会进行一致性检查,损坏会尝试修复,可能会花很长时间;表中最后一项可能是损坏的会丢失。
表的类型
ETS 和 DETS 表保存的是元组。元组里的某一个元素(默认是第一个)被称为该表的键。
- 异键表(set):表里所有的键都是唯一的
- 有序异键(ordered set):元组会被排序
- 同键表(bag):允许多个元素拥有相同的键
- 副本同键(duplicate bag):可以有多个元组拥有相同的键,而且在同一张表里可以存在多个相同的元组
-module(ets_test).
%% API
-export([start/0]).
start() ->
lists:foreach(fun test_ets/1, [set, ordered_set, bag, duplicate_bag]).
test_ets(Mode) ->
TableId = ets:new(test, [Mode]),
ets:insert(TableId, {a, 1}),
ets:insert(TableId, {b, 2}),
ets:insert(TableId, {a, 1}),
ets:insert(TableId, {a, 3}),
List = ets:tab2list(TableId),
io:format("~-13w => ~p~n", [Mode, List]),
ets:delete(TableId).
λ erl
Eshell V12.3.2.1 (abort with ^G)
1> c(ets_test).
{ok,ets_test}
2> ets_test:start().
set => [{b,2},{a,3}]
ordered_set => [{a,3},{b,2}]
bag => [{b,2},{a,1},{a,3}]
duplicate_bag => [{b,2},{a,1},{a,1},{a,3}]
ok
影响 ETS 表效率的因素
ETS 表在内部是用散列表表示的,(ordered set)用平衡二叉树表示。
保存元组到磁盘
Mnesia:Erlang 数据库
Mnesia是一种用Erlang编写的数据库。
Mnesia的速度极快,可以保存任何类型的Erlang数据结构。它还是高度可定制的。数据表既可以保存在内存里(为了速度),也可以保存在磁盘上(为了持久性)。表还可以在不同机器之间进行复制,从而实现容错行为。
创建初始数据库
$ erl
% mnesia:create_schema(NodeList) 会在 Erlang 节点列表的所有节点上都初始化一个新的 Mnesia 数据库,会初始化并且创建一个目录结构来保存
1> mnesia:create_schema([node()]).
ok
2> init:stop().
ok
$ ls
Mnesia.nonode@nohost
# 创建名为 joe 的 erlang 节点
$ erl -sname joe
# 启动 erlang 时指向一个特定的数据库
$ erl -mnesia dir '"/home/joe/some/path/to/Mnesia.company"'
数据库查询
-module(test_mnesia).
-import(lists, [foreach/2]).
-compile(export_all).
%% IMPORTANT: The next line must be included
%% if we want to call qlc:q(...)
-include_lib("stdlib/include/qlc.hrl").
% Mnesia 里的表是一个包含若干行的**异键或同键表**,其中每一行都是**一个 Erlang 记录**。要在 Mnesia 里表示这些表,需要一些**记录定义**来对表里的行进行定义。
-record(shop, {item, quantity, cost}).
-record(cost, {name, price}).
-record(design, {id, plan}).
%% 初始化数据表
do_this_once() ->
mnesia:create_schema([node()]),
mnesia:start(),
mnesia:create_table(shop, [{attributes, record_info(fields, shop)}]),
mnesia:create_table(cost, [{attributes, record_info(fields, cost)}]),
mnesia:create_table(design, [{attributes, record_info(fields, design)}]),
mnesia:stop().
start() ->
mnesia:start(),
mnesia:wait_for_tables([shop,cost,design], 20000).
%% SQL equivalent
%% SELECT * FROM shop;
demo(select_shop) ->
do(qlc:q([X || X <- mnesia:table(shop)]));
%% SQL equivalent
%% SELECT item, quantity FROM shop;
demo(select_some) ->
do(qlc:q([{X#shop.item, X#shop.quantity} || X <- mnesia:table(shop)]));
%% SQL equivalent
%% SELECT shop.item FROM shop
%% WHERE shop.quantity < 250;
demo(reorder) ->
do(qlc:q([X#shop.item || X <- mnesia:table(shop),
X#shop.quantity < 250
]));
%% SQL equivalent
%% SELECT shop.item
%% FROM shop, cost
%% WHERE shop.item = cost.name
%% AND cost.price < 2
%% AND shop.quantity < 250
demo(join) ->
do(qlc:q([X#shop.item || X <- mnesia:table(shop),
X#shop.quantity < 250,
Y <- mnesia:table(cost),
X#shop.item =:= Y#cost.name,
Y#cost.price < 2
])).
do(Q) ->
F = fun() -> qlc:e(Q) end,
{atomic, Val} = mnesia:transaction(F),
Val.
example_tables() ->
[%% The shop table
{shop, apple, 20, 2.3},
{shop, orange, 100, 3.8},
{shop, pear, 200, 3.6},
{shop, banana, 420, 4.5},
{shop, potato, 2456, 1.2},
%% The cost table
{cost, apple, 1.5},
{cost, orange, 2.4},
{cost, pear, 2.2},
{cost, banana, 1.5},
{cost, potato, 0.6}
].
add_shop_item(Name, Quantity, Cost) ->
Row = #shop{item=Name, quantity=Quantity, cost=Cost},
F = fun() ->
mnesia:write(Row)
end,
mnesia:transaction(F).
remove_shop_item(Item) ->
Oid = {shop, Item},
F = fun() ->
mnesia:delete(Oid)
end,
mnesia:transaction(F).
farmer(Nwant) ->
%% Nwant = Number of oranges the farmer wants to buy
F = fun() ->
%% find the number of apples
[Apple] = mnesia:read({shop,apple}),
Napples = Apple#shop.quantity,
Apple1 = Apple#shop{quantity = Napples + 2*Nwant},
%% update the database
mnesia:write(Apple1),
%% find the number of oranges
[Orange] = mnesia:read({shop,orange}),
NOranges = Orange#shop.quantity,
if
NOranges >= Nwant ->
N1 = NOranges - Nwant,
Orange1 = Orange#shop{quantity=N1},
%% update the database
mnesia:write(Orange1);
true ->
%% Oops -- not enough oranges
mnesia:abort(oranges)
end
end,
mnesia:transaction(F).
reset_tables() ->
mnesia:clear_table(shop),
mnesia:clear_table(cost),
F = fun() ->
foreach(fun mnesia:write/1, example_tables())
end,
mnesia:transaction(F).
add_plans() ->
D1 = #design{id = {joe,1},
plan = {circle,10}},
D2 = #design{id = fred,
plan = {rectangle,10,5}},
D3 = #design{id = {jane,{house,23}},
plan = {house,
[{floor,1,
[{doors,3},
{windows,12},
{rooms,5}]},
{floor,2,
[{doors,2},
{rooms,4},
{windows,15}]}]}},
F = fun() ->
mnesia:write(D1),
mnesia:write(D2),
mnesia:write(D3)
end,
mnesia:transaction(F).
get_plan(PlanId) ->
F = fun() -> mnesia:read({design, PlanId}) end,
mnesia:transaction(F).
性能分析、调试与跟踪
Erlang 代码的性能分析工具
- cprof 统计各个函数被调用的次数。它是一个轻量级的性能分析器,在活动系统上运行它会增加 5%~ 10% 的系统负载。
- fprof显示调用和被调用函数的时间,结果会输出到一个文件。它适用于实验室或模拟系统里的大型系统性能分析,并会显著增加系统负载。
- eprof 测量 Erlang 程序是如何使用时间的。它是 fprof 的前身,适用于小规模的性能分析。
(scarb@DESKTOP-72654G4)5> cprof:start().
9795
(scarb@DESKTOP-72654G4)6> shout:start().
** exception error: undefined function shout:start/0
(scarb@DESKTOP-72654G4)7> mnesia:stop().
stopped
(scarb@DESKTOP-72654G4)8> cprof:pause().
9795
(scarb@DESKTOP-72654G4)9> cprof:analyse(mnesia).
{mnesia,1,[{{mnesia,stop,0},1}]}
运行时诊断
deliberate_error(A) ->
bad_function(A, 12),
lists:reverse(A).
bad_function(A, _) ->
{ok, Bin} = file:open({abc,123}, A),
binary_to_list(Bin).

错误消息之后是栈跟踪信息。它以发生错误的函数名开头,后面是当前函数完成后将会返回的各个函数清单(包括函数名、模块名和行号)。由此可知,错误发生在 lib_misc:bad_function/2 里,而此函数将会返回到 lib_misc:deliberate_error/1,以此类推。
调试方法
io:format 调试
给程序添加打印语句是最常见的调试形式。可以简单地在程序的关键位置添加 io:format(...) 语句来打印出感兴趣的变量值。
调试并行程序时,一种好的做法是在发送消息到别的进程之前先把它打印出来,收到消息之后也要立即打印。
转储至文件
dump(File, Term) ->
Out = File ++ ".tmp",
io:format("** dumping to ~s~n",[Out]),
{ok, S} = file:open(Out, [write]),
io:format(S, "~p.~n",[Term]),
file:close(S).
Erlang 调试器
跟踪消息与进程执行
erlang:trace(PidSpec, How, FlagList)
它会启动跟踪。PidSpec告诉系统要跟踪什么进程,How是一个开启或关闭跟踪的布尔值,FlagList指定了要跟踪的事件(比如,可以跟踪所有的函数调用,跟踪所有正在发送的消息,跟踪垃圾收集何时进行,等等)。
一旦调用了erlang:trace/3这个内置函数,调用它的进程就会在跟踪事件发生时收到跟踪消息。跟踪事件本身是通过调用erlang:trace_pattern/3确定的。erlang:trace_pattern(MFA, MatchSpec, FlagList)
它用于设置一个跟踪模式。如果模式匹配,请求的操作就会执行。这里的MFA是一个{Module, Function, Args}元组,指定要对哪些代码应用跟踪模式。 MatchSpec是一个模式,会在每次进入MFA指定的函数时进行测试,而FlagList规定了跟踪条件满足时要
做什么。
可以用库模块 dbg 来执行与之前相同的跟踪。
fib(0) -> 1;
fib(1) -> 1;
fib(N) -> fib(N - 1) + fib(N - 2).
test1() ->
dbg:tracer(),
dbg:tpl(tracer_test, fib, '_',
dbg:fun2ms(fun(_) -> return_trace() end)),
dbg:p(all, [c]),
tracer_test:fib(4).
OTP 介绍
Open Telecom Platform(开放电信平台),它是一个应用程序操作系统,包含了一组库和实现方式,可以构建大规模、容错和分布式的应用程序。它由瑞典电信公司爱立信开发,在爱立信内部用于构建容错式系统。标准的Erlang分发套装包含OTP库。
OTP 包含了许多强大的工具,例如一个完整的 Web 服务器,一个FTP服务器和一个 CORBAORB 等。
欢迎关注公众号【消息中间件】(middleware-mq),更新消息中间件的源码解析和最新动态!
