
PowerJob 原理详解 & 源码解析
原文地址:http://hscarb.github.io/other/20230820-powerjob.html
PowerJob 原理详解 & 源码解析
作者:zmt-Eason
PowerJob是新一代分布式任务调度与计算框架,支持CRON、API、固定频率、固定延迟等调度策略,提供工作流来编排任务解决依赖关系,能让用户轻松完成作业的调度与繁杂任务的分布式计算。
1. 为什么选择Powerjob
当前比较流行的开源调度框架包括Quartz、elasticjob、xxl-job等。Quartz可以认为是第一代调度框架,不提供Web页面,只能通过API完成任务配置,更多地是支持单机场景的调度,在分布式场景下需要基于DB锁进行任务执行,性能会有瓶颈。
摘下网上的一幅图,给出了各个开源调度中间件的对比:
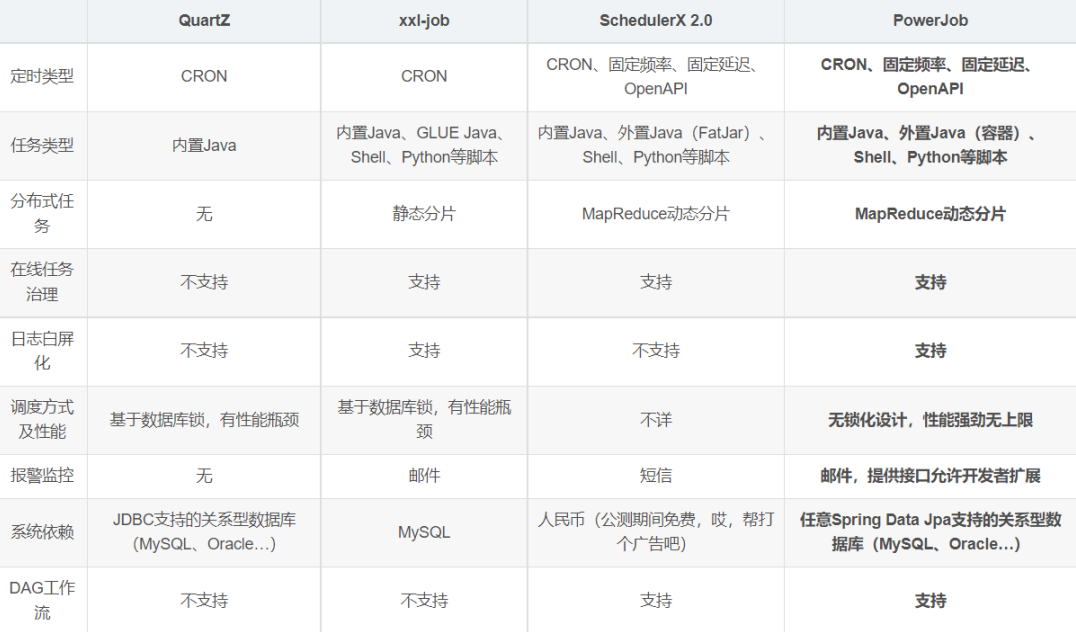
以下是官方列出的主要特性:
- 使用简单: 提供前端Web界面,允许开发者可视化地完成调度任务的管理(增、删、改、查)、任务运行状态监控和运行日志查看等功能。
- 定时策略完善: 支持CRON表达式、固定频率、固定延迟和API四种定时调度策略。
- 执行模式丰富: 支持单机、广播、Map、MapReduce四种执行模式,其中Map/MapReduce处理器能使开发者寥寥数行代码便获得集群分布式计算的能力。
- DAG工作流支持: 支持在线配置任务依赖关系,可视化得对任务进行编排,同时还支持上下游任务间的数据传递
- 执行器支持广泛: 支持Spring Bean、内置/外置Java类、Shell、Python等处理器,应用范围广。
- 运维便捷: 支持在线日志功能,执行器产生的日志可以在前端控制台页面实时显示,降低debug成本,极大地提高开发效率。
- 依赖精简: 最小仅依赖关系型数据库(MySQL/PostgreSQL/Oracle/MS SQLServer…),同时支持所有Spring Data JPA所支持的关系型数据库。
- 高可用&高性能: 调度服务器经过精心设计,一改其他调度框架基于数据库锁的策略,实现了无锁化调度。部署多个调度服务器可以同时实现高可用和性能的提升(支持无限的水平扩展)。
- 故障转移与恢复: 任务执行失败后,可根据配置的重试策略完成重试,只要执行器集群有足够的计算节点,任务就能顺利完成。
其适用场景如下:
- 有定时执行需求的业务场景:如每天凌晨全量同步数据、生成业务报表等。
- 有需要全部机器一同执行的业务场景:如使用广播执行模式清理集群日志。
- 有需要分布式处理的业务场景:比如需要更新一大批数据,单机执行耗时非常长,可以使用Map/MapReduce处理器完成任务的分发,调动整个集群加速计算。
powerjob从架构和技术选型上较大程度参考了schedulerX,个人觉得比较好用的点主要在于一个在于支持代码中自定义实现MapReduce动态分片。MapReduce就是一个任务切分多个子任务并行处理。在简单单机场景下就是开启多线程来同时处理一个大任务,在多个机器下可以有多台机器同时并行处理同一个任务,分布式调度的MapReduce模型就是为使用者在代码开发层面屏蔽上述并行协调的逻辑,让使用者可以通过简单的业务逻辑开发完成并行任务设计开发。此外,还支持在线日志功能,能够在控制台上统一看到所有worker上报的日志,方便运维。
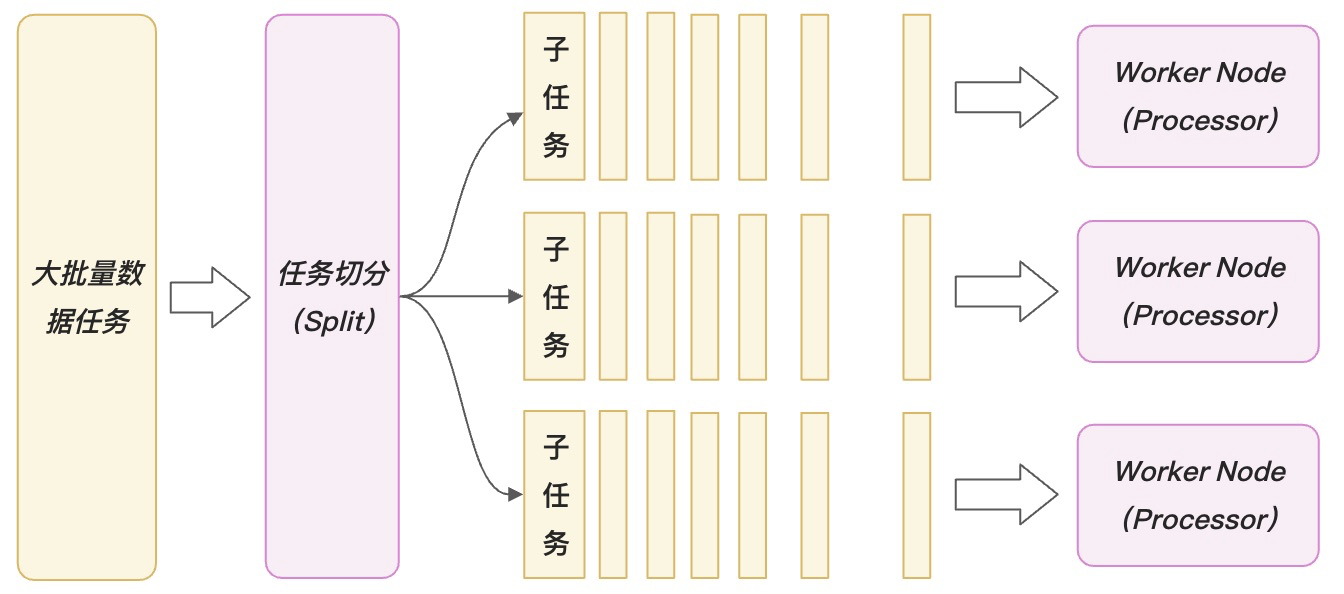
2. 架构解析
PowerJob 引入了调度中心来统一解决任务的配置和调度,整个系统由调度中心(powerjob-server)和执行器(powerjob-worker)构成。
调度中心是一个基于 SpringBoot 的 Web 应用,根据提供服务的对象可以划分为对外和对内两层。对外部分面向用户,即提供 HTTP 服务,允许开发者在前端界面上可视化完成任务、工作流等信息的配置与管理;对内部分则负责完成开发者所录入任务的调度和派发,同时维护注册到本注册中心所有执行器集群的状态。
执行器是一个普通的 Jar 包,需要接入调度中心的应用依赖该 Jar 包并完成初始化后,powerjob-worker 便正式启动并提供服务。执行器的整体逻辑就是监听来自调度中心的任务执行请求,一旦接收到任务就开始分配资源、初始化执行器开始处理,同时维护着一组后台线程定期上报自身的健康状态、任务执行状态。
调度中心和执行器之间通过 akka-remote 进行通讯。Akka 是一个基于 Actor 模型的并发和分布式计算工具包,主要用于构建高并发、分布式、容错性高的系统,其用于远程通信的优势如下:
- 提高开发效率:Akka 通过提供统一的地址方案实现了 Actor 之间的通信位置透明性,无论 Actor 是在本地还是远程,都可以使用相同的方式来通信。并且实现起来非常简洁,通过一两句代码就能实现可靠、异步的远程通信。
- 高并发性:基于轻量级的 Actor 模型,Akka 可以轻松地支持数百万并发 Actor 实例,从而实现高并发。
- 容错性:Akka 提供了“let it crash”策略,通过使用 Actor 的监控机制,当 Actor 发生故障时可以进行自动恢复。
- 异步解耦:Actor 之间的所有通信都是通过异步消息传递实现的,这避免了传统的锁和线程同步以及资源竞争问题。
调度中心可以多实例部署来做到调度中心高可用,执行器也可以通过集群部署实现高可用,同时,如果开发者实现了 MapReduce 这一具有分布式处理能力的处理器,也可以调动整个集群的计算资源完成任务的分布式计算。
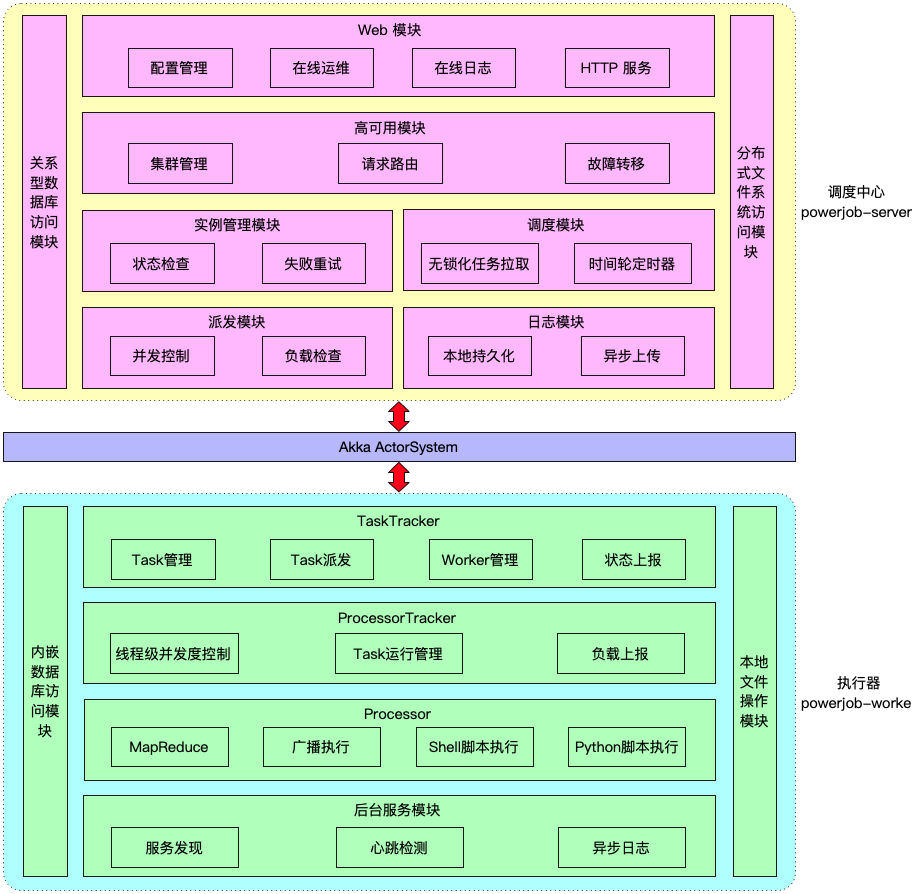
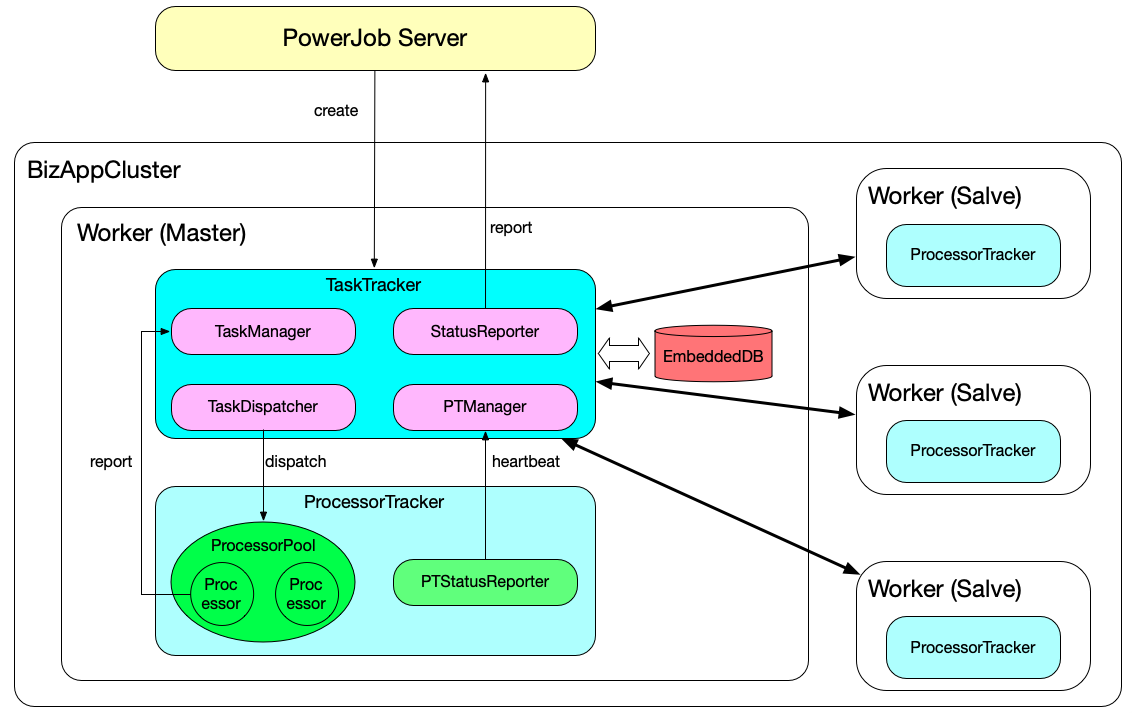
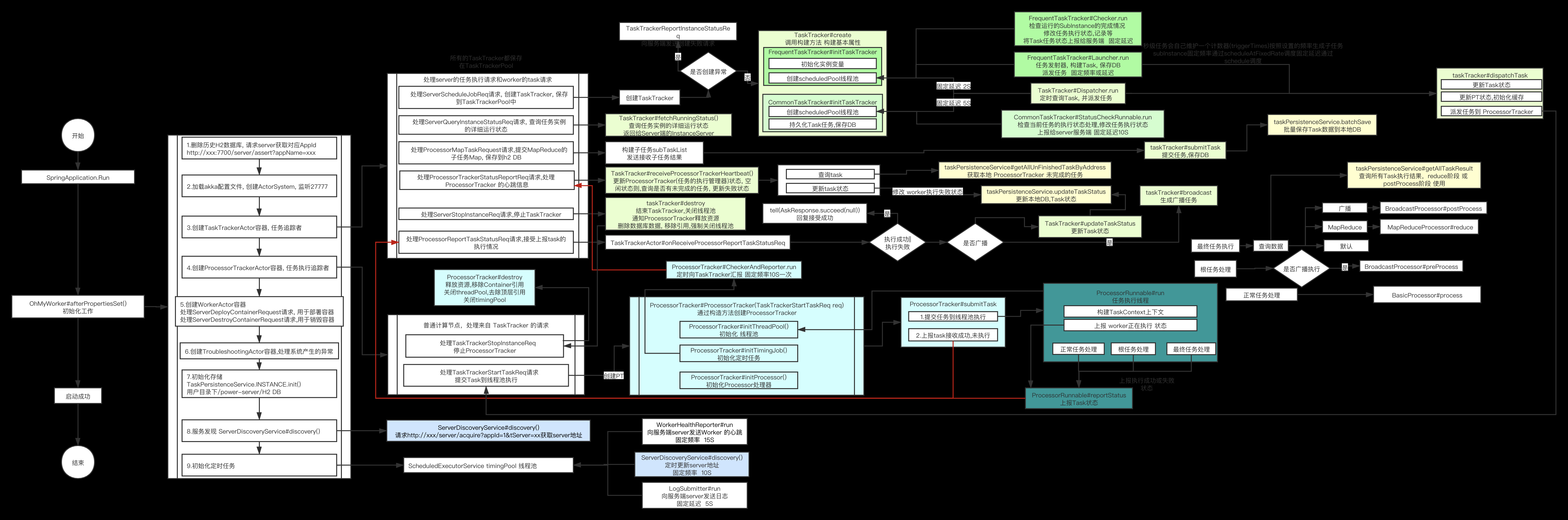
为了便于模型的设计和功能的划分,PowerJob 为执行器节点分配了 3 种角色,分别是 TaskTracker、ProcessorTracker 和 Processor。
- TaskTracker 是每一个任务的主节点,充当worker集群中的 master 角色,每个任务每次只会产生一个 TaskTracker。它负责如Map子任务的分发、状态监控和集群中各执行节点的健康检查,并定期将任务的运行时信息上报给 server。当需要执行分布式任务时,powerjob-server 会根据集群中各个 worker 节点的内存占用、CPU 使用率和磁盘使用率进行健康度计算,得分最高的节点将作为本次任务的 master 节点,即承担 TaskTracker 的职责。
- ProcessorTracker 是每一个执行器节点中负责执行器管理的角色,每个任务在每个执行器节点(JVM 实例)上都会产生一个 ProcessorTracker。它负责管理执行器节点任务的执行,包括接受来自 TaskTracker 的任务、上报本机任务执行情况和执行状态等功能。
- Processor 是每一个执行器节点中负责具体执行任务的角色,也就是真正的执行单元,每个任务在每个执行器节点都会生成若干个 Processor。控制台上可以控制“实例并发数”,也就是每个节点上Processor最大的数量,它接受来自 ProcessorTracker 派发的执行任务并完成计算。
3. 关键流程解析
后续源码解析基于4.3.3版本
3.1 server初始化流程
以下是官方提供的server初始化流程图
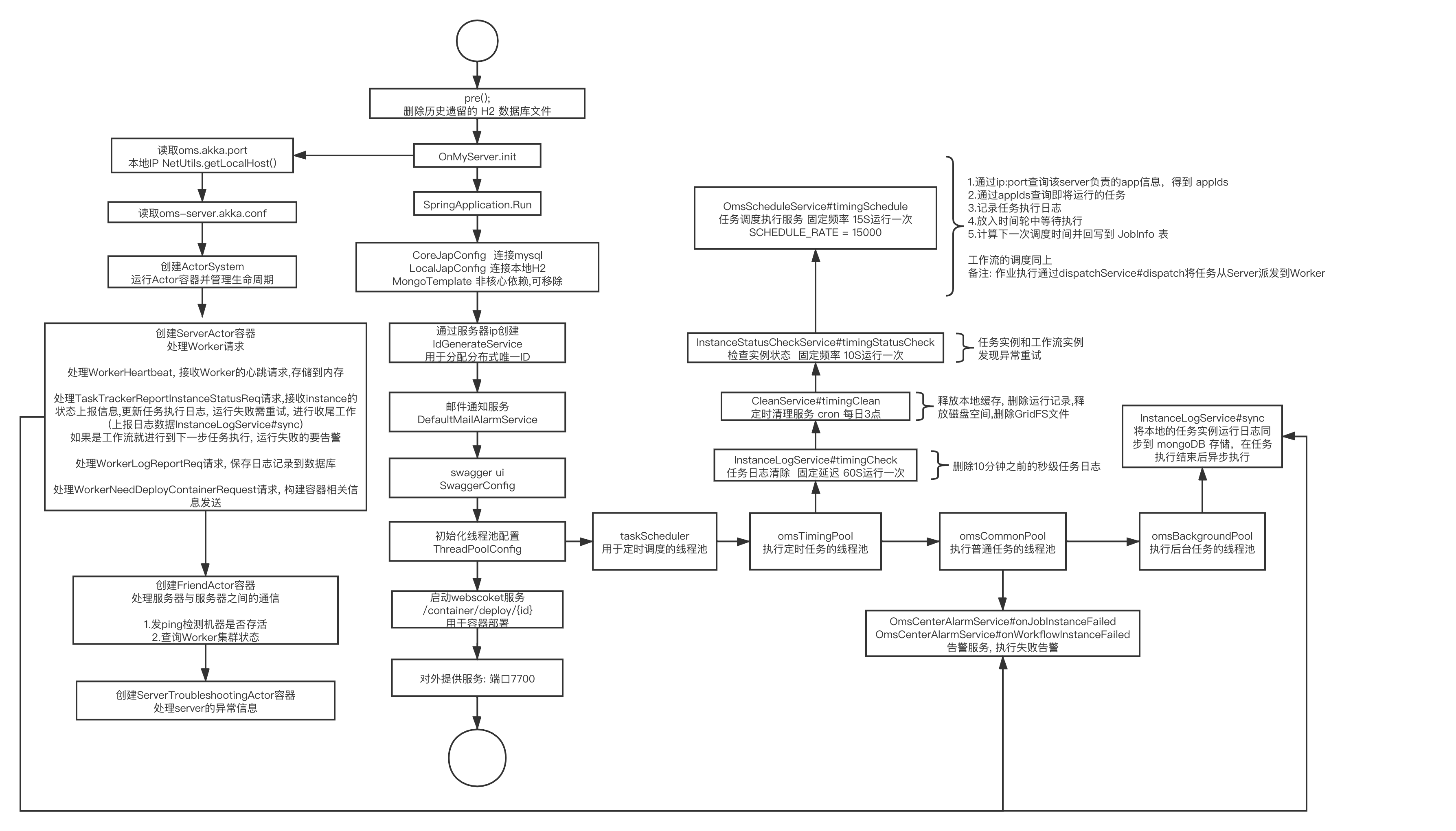
主要关注两个部分:
CoreScheduleTaskManager类负责管理所有调度的任务,在server初始化时,该类拉起了调度、状态检查、数据清理的定时线程。
不同调度线程的逻辑较为类似,以PowerScheduleService#scheduleNormalJob0方法为例,该方法逻辑如下:
查询本server负责的所有appId列表
以任务开启 + 指定调度类型(CRON、DAILY_TIME_INTERVAL) + 指定appId + 即将需要调度执行为条件查询jobInfo表,查出所有待执行的job
创建任务实例InstanceInfo,初始化status为WAITING_DISPATCH等待派发,推入时间轮等待运行
计算下一次调度时间,更新jobInfo
看到这里可能有疑问,如果在一个周期内job要执行多次,这里只会插入一个任务实例执行一次,那么剩余的任务实例是否就没有调度了?以上逻辑只适用于cron和DAILY_TIME_INTERVAL这类任务,其中CRON 表达式最小间隔 15S,高频率执行则使用秒级任务 FIXED_RATE 和 FIXED_DELAY,由如下方法处理。
处理秒级任务的scheduleFrequentJobCore流程如下:
- 查询本server负责的所有appId列表
- 从jobInfo表查询所有enable状态的秒级任务,从日志表InstanceInfo中查询运行状态的jobId
- 对于未运行的job,根据生命周期计算是否需要执行,并计算delay后放入时间轮或立即执行。
秒级任务在任务正常运行状态只会在日志表产生一条运行记录,server端只是负责拉起这个任务,把后续执行的动作都放到了worker端,worker相当于会启动定期任务去执行秒级任务。这样设计的初衷应该是考虑到秒级任务执行频率较大,每次由server去调度代价太大。
状态检查线程负责定时查询任务运行后一定时间内还处于运行中、等待派发、等待worker接受状态的任务,并根据任务类型、任务配置重试策略的判断是否发起重试。
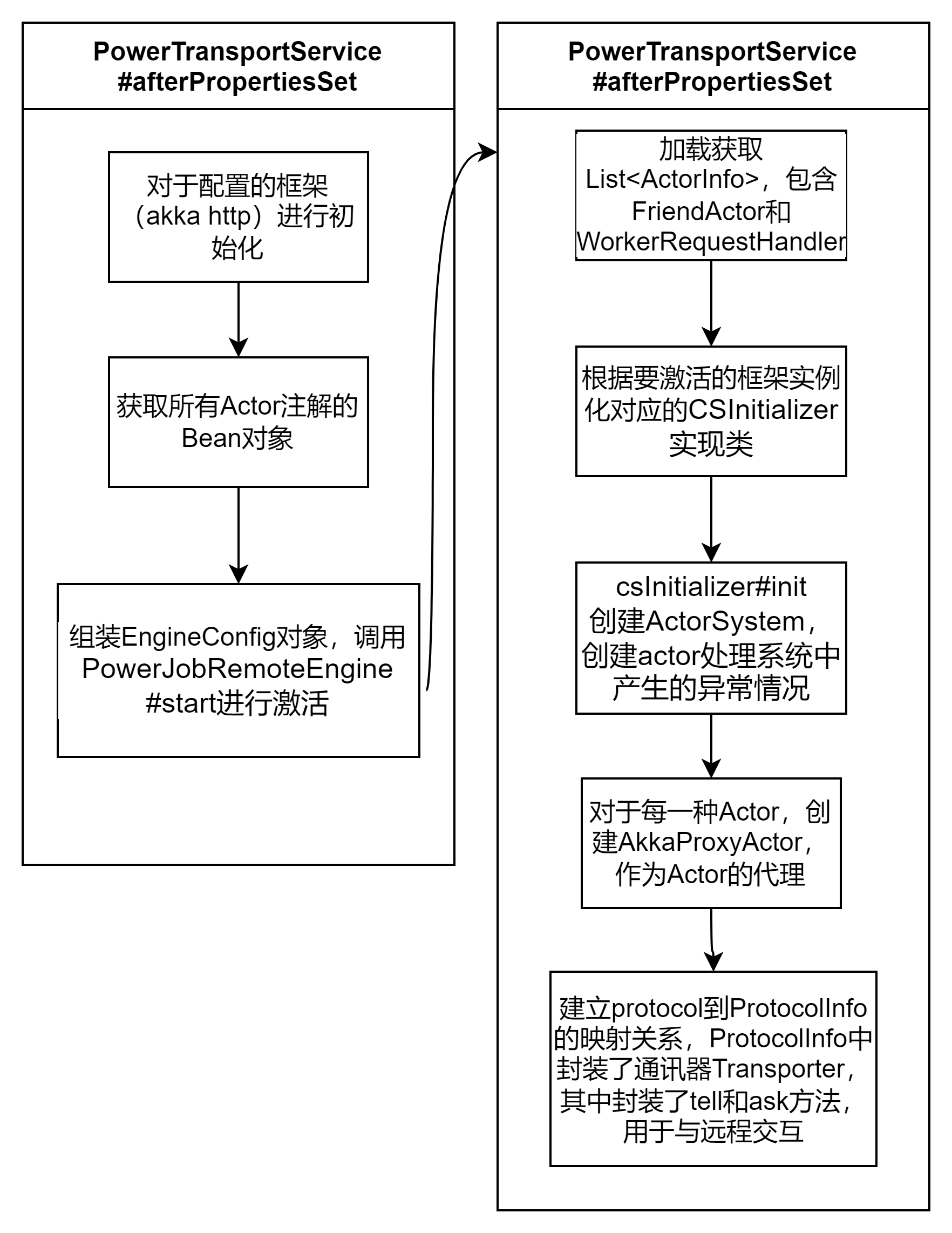
server网络通信层初始化
该部分负责将配置的protocol进行激活初始化,目前支持的protocol包括akka和http(基于vertx实现)。以akka为例,下图为初始化流程,server端主要对两种Actor,FriendActor和WorkerRequestHandler进行actor与handler方法的绑定,前者负责服务端与服务端的通讯,如用于探测是否存活的ping请求,后者负责处理接受worker端发来的通讯请求。
3.2 worker初始化流程
worker全流程图如下(源自官网):
如果在任务执行过程中增加了worker,此时新worker会向server发送心跳,server在下一次下发ServerScheduleJobReq请求时会携带最新worker信息:
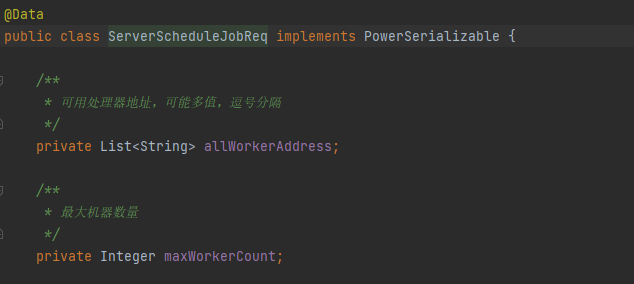
image-20230808222542658 对于秒级任务和MAP、MapReduce任务,TaskTracker会动态加载最新worker列表。
如果执行过程中worker下线,那么这个任务实例的状态就停留在DISPATCH_SUCCESS_WORKER_UNCHECK或WAITING_DISPATCH或WORKER_RECEIVED状态,tasktracker定期任务检测到该instance任务的processorTracker长时间未更新上报状态,会重新分发。TaskTracker分发任务的时候,会分发给可用的ProcessorTracker(1分钟内未上报会被移除出可用worker列表),这样,丢失的任务会被TaskTracker重新分发到可用的worker去,保证任务不丢失。
3.3 创建Job
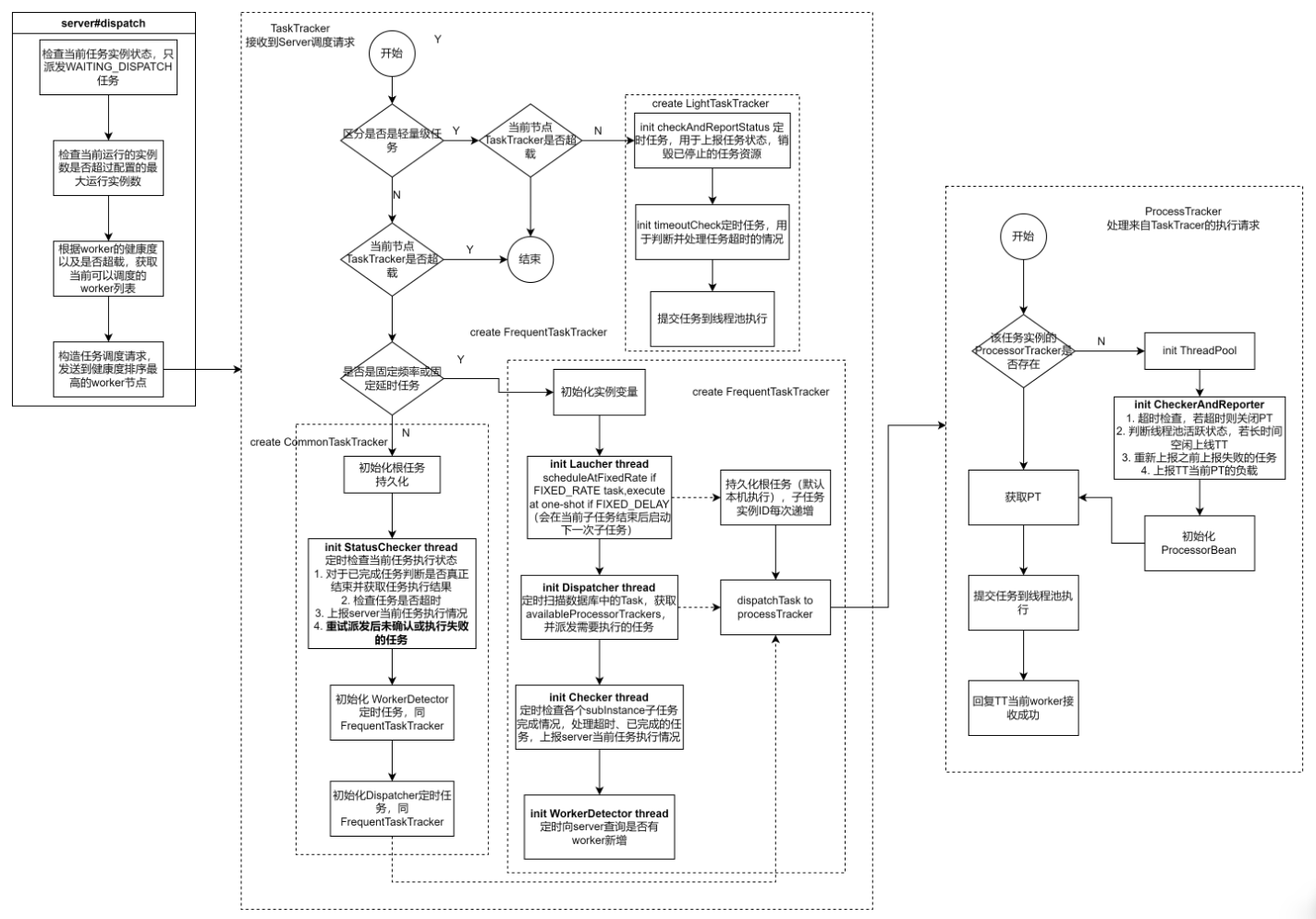
4.源码解析
4.1 MapReduce动态分片
- 动态注册最新worker列表
TaskTracker逻辑中,对于MAP、MapReduce以及秒级任务会起一个定时线程,每隔一分钟探测是否需要加载新的worker,逻辑如下:
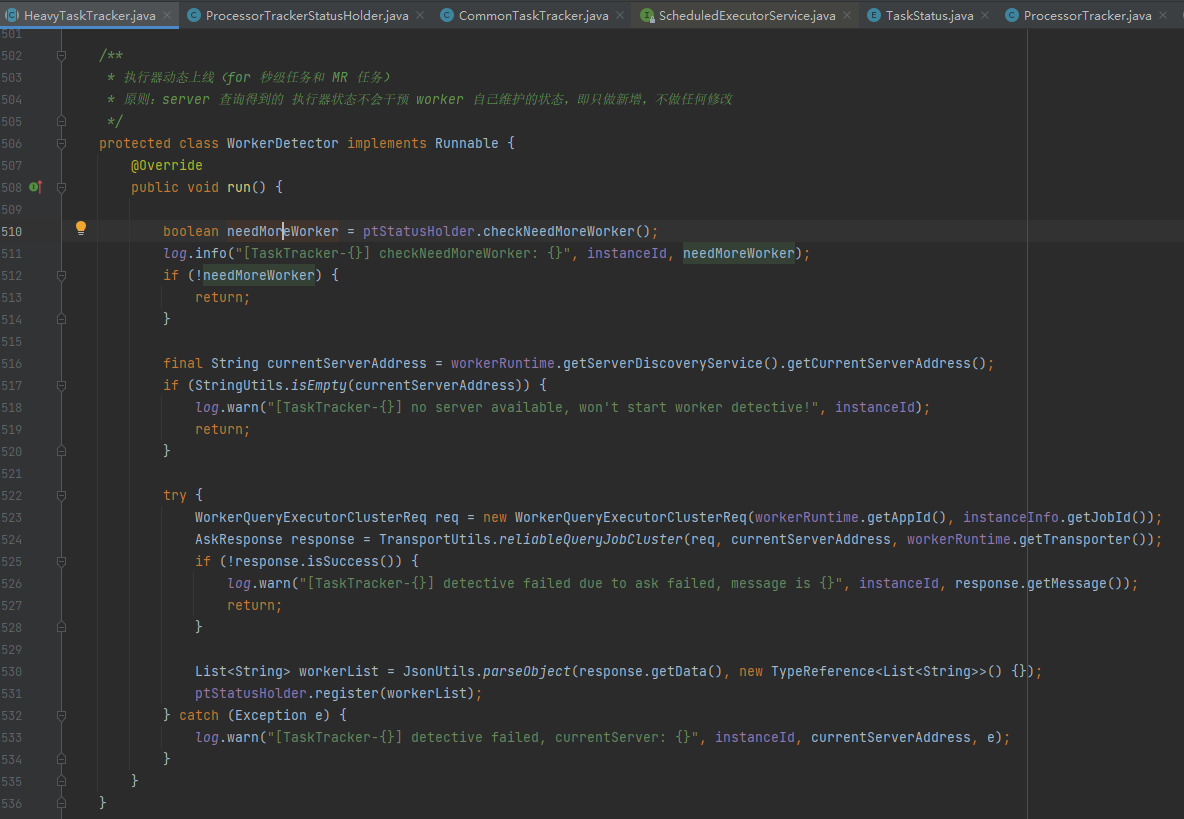
首先判断当前可用的worker节点数是否达到了maxWorkerCount,如果未达到则请求server获取最新的可用worker列表,对于新的worker进行注册逻辑。这样每次有新的worker上线,可以将子任务分发给新的worker去计算,从而充分调度整个集群的能力
分发子任务
调用map方法时,构造了ProcessorMapTaskRequest请求发送给TaskTracker,源码见MapProcessor接口的map方法。TaskTracker接收到请求后,会将子任务初始化为WAITING_DISPATCH状态插入TaskDo表,等待调度器调度。
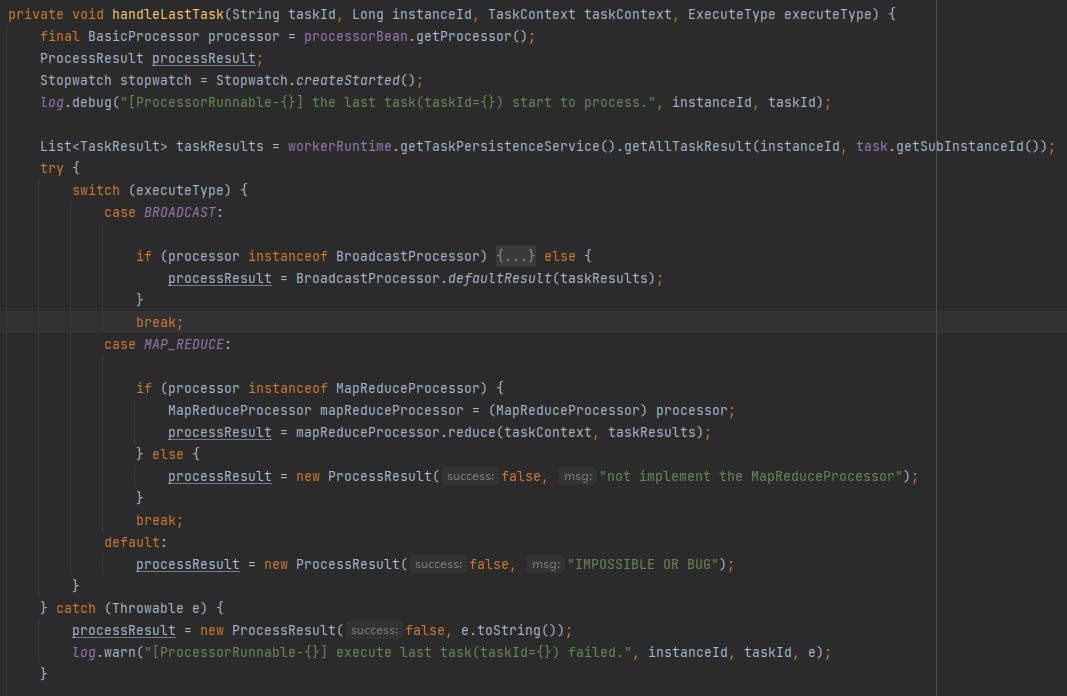
TaskTracker的检查任务执行情况的定时任务中,若判断当前任务所有子任务已结束,对于MAP不关心结果,对于MapReduce任务会执行LAST_TASK任务,如下代码:

在ProcessorTracker中判断是LAST_TASK,则执行最终任务,此任务的实现交给用户去定义,代码如下:
4.2 时间轮
在PowerScheduleService#scheduleNormalJob0方法中,会查询即将需要调度执行的任务,这里的阈值是30秒,也就是将30秒内即将执行的任务加载到时间轮中待执行,并更新下一次触发时间。

InstanceTimeWheelService类中定义了两个时间轮:

其中TIMER用于精确调度,精确度为1ms(受限于sleep方法的精度无法更加提高),而SLOW_TIMER则用于加载高延迟的任务,它的精确度为10s,下面看下schedule方法是怎么实现的:
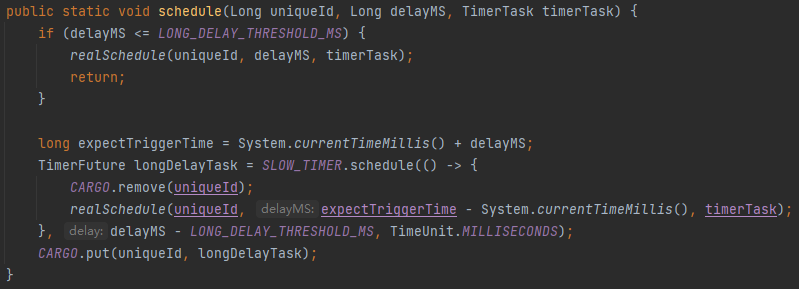
这里实现了多级时间轮:首先判断了delayMS的时长,如果小于60s,会调用realSchedule,加载到TIMER时间轮中等待调度,而对于长周期的方法,也就是大于1分钟后等待调度的,则放入SLOW_TIMER时间轮等待调度,这里有意思的是,被SLOW_TIMER到期触发的逻辑就是realSchedule方法。试想下,如果把所有任务都加载到TIMER这个高精度时间轮,由于这种高精度的时间轮需要频繁地检查和执行任务,这在 CPU 资源上可能是昂贵的,这样设计可以减少资源消耗,提高资源利用率。
时间轮的实现在timewheel包下,目录如下:
其UML类图如下:
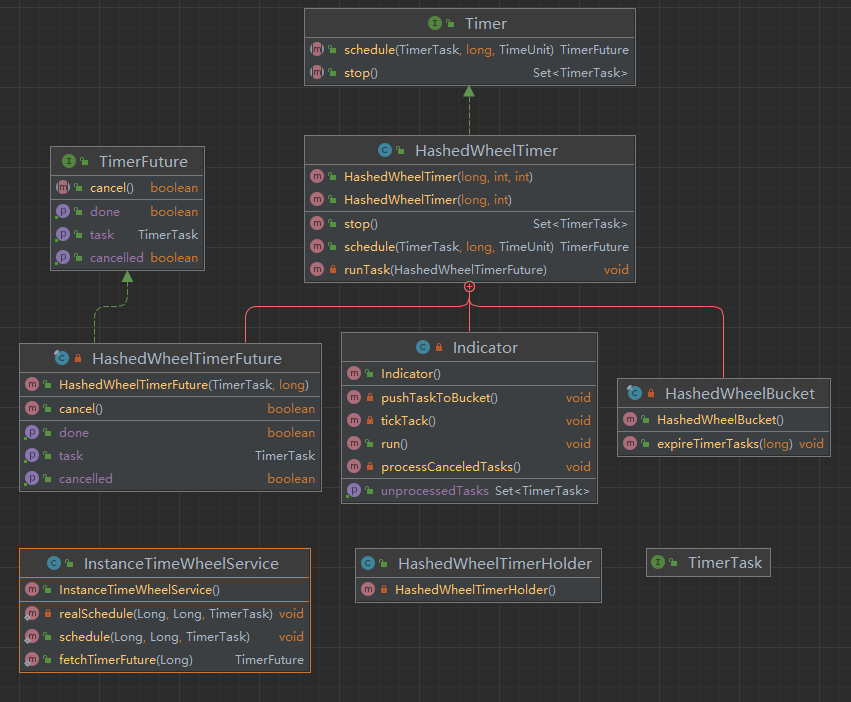
可以看到HashedWheelTimer是最为关键的类,这个类的初始化做了以下几件事:
- 初始化轮盘,这里轮盘个数为2的N次方,为了后续可以通过&取余高效地计算任务在时间轮的所属下标;
- 初始化执行线程池taskProcessPool,用于执行时间轮到期的任务;
- 启动后台线程Indicator。
这里Indicator线程模拟了指针的转动,其逻辑如下:
- 不断地将任务从waitingTasks队列推入时间轮,waitingTasks是一个LinkedBlockingQueue数据结构,其中存放的元素是HashedWheelTimerFuture,它包装了等待执行的TimerTask,维护了预期执行时间以及任务的状态(等待、运行中、完成、取消)。由于LinkedBlockingQueue是线程安全的,所以统一由Indicator线程从队列中取数据,计算在时间轮中的index下标,并添加到对应时间格的任务链表中;
- 处理取消的任务。这里逻辑同上类似,也是不断地从LinkedBlockingQueue类型的canceledTasks队列中取数据,并从时间格的任务链表中删除对应任务;
- 模拟指针转动,计算当前时间距离下一个时间格的时间,并执行sleep;
- 从当前时间格的任务链表中取出待执行的任务,提交到taskProcessPool线程池中执行。
schedule方法的逻辑比较简单,并判断如果是已经到期或者过期任务,则直接执行,否则计算任务的目标执行时间,初始化HashedWheelTimerFuture对象并添加到waitingTasks队列,等待Indicator任务去取数据。
4.3 无锁化设计和高可用的关键:分组隔离机制
powerjob的特性上有一个比较有趣的点:无锁化设计,性能强劲无上限。下面就来看看它是如何实现的。
worker的初始化方法中,有这么一段代码,调用了ServerDiscoveryService的start方法:
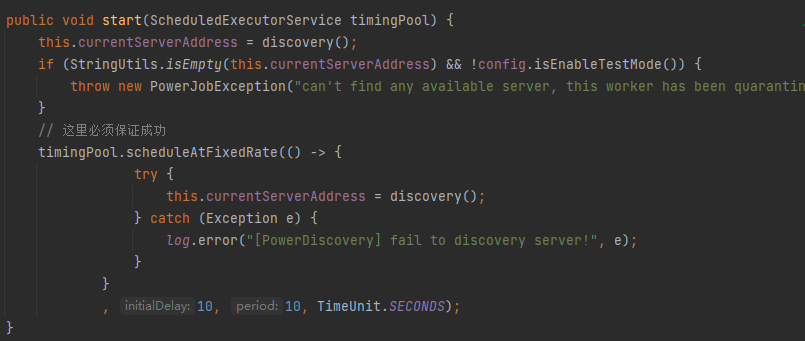
这里定时调用discovery方法,下面看下这个方法的逻辑:
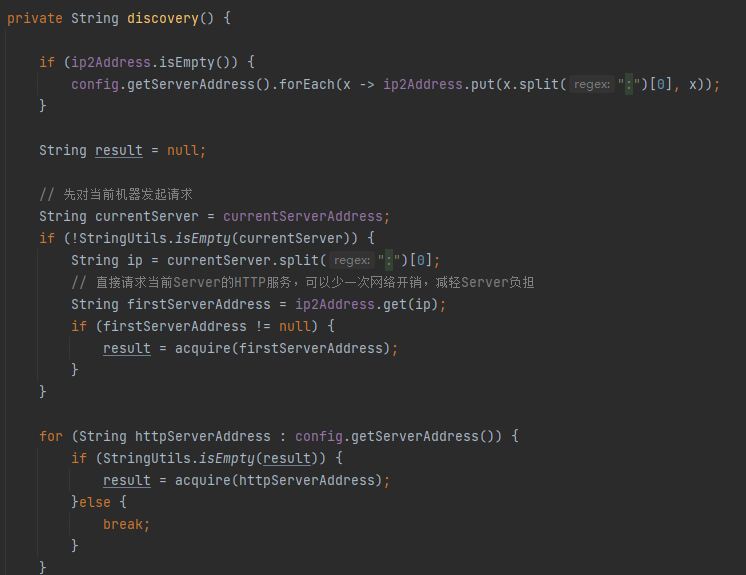
这里就是根据worker配置的server的ip列表去请求,调用/acquire方法,下面看下server的这个方法做了什么事情,用一张流程图归纳:
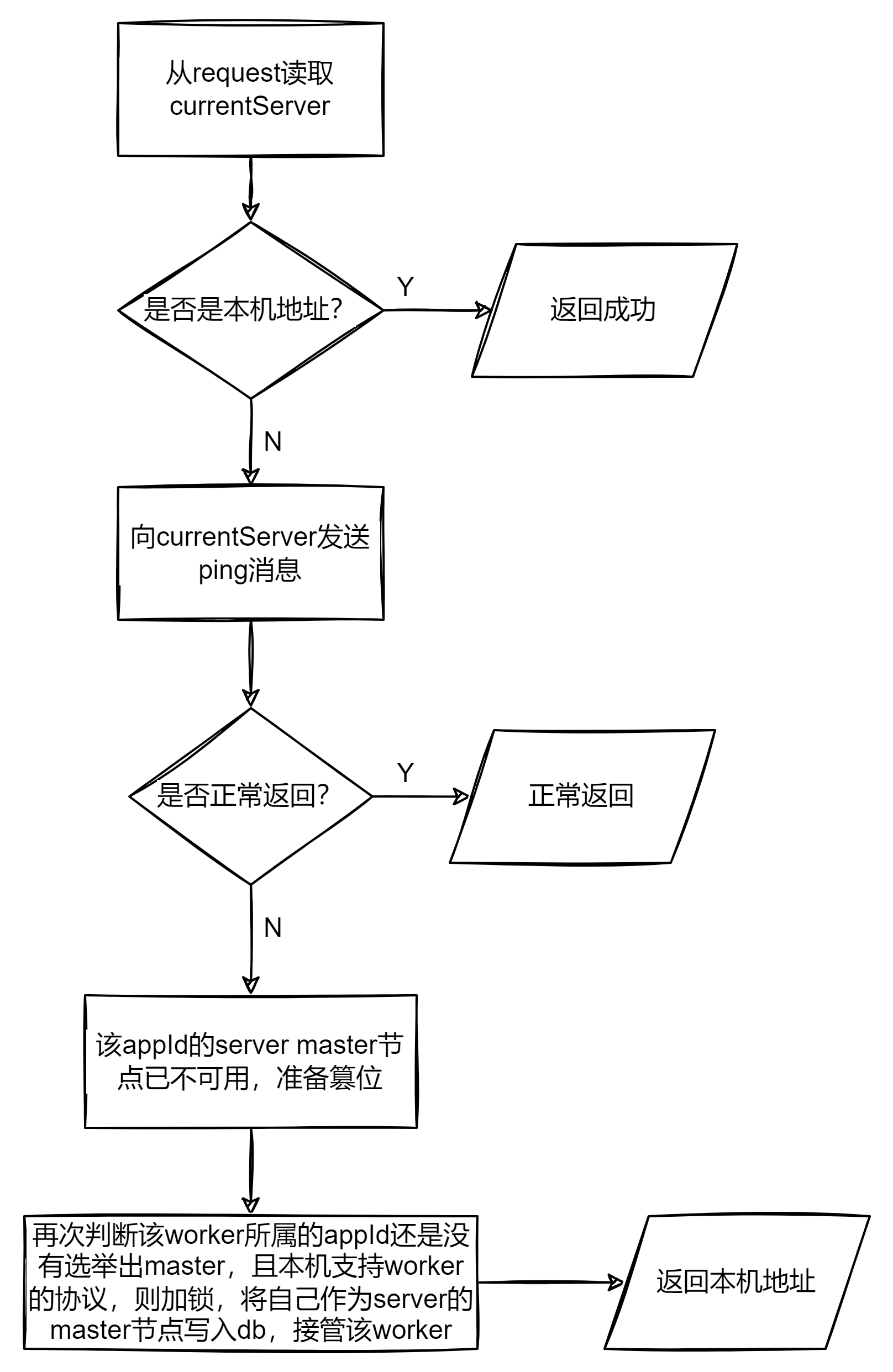
也就是说一个appId分组下所有worker都是由一个server节点去接管,这样避免了多个server通过加锁来抢占调度任务的情况,这里的appId逻辑分组概念比较类似RocketMQ的ConsumerGroup。这样就形成了一个小型的子系统,虽然整个 PowerJob 系统中存在着多台 server 和多个 worker 集群,但是对于这个分组的运行来说,只要有这个分组对应的 worker 集群以及它们连接的那一台 server 就够了。那么在这个小型“子系统”内部,只存在着一台 server,也就不存在重复调度问题了,这台server连接着这个分组下所有的worker,负责所有worker的调度。同时,也在没有引入其它中间件的情况下实现了高可用,一旦server的master节点异常,马上就可以由其它可用server去接管。
可以看出,如果某一时刻要调度的worker达到一定量级,那么server的性能就会成为瓶颈。对于这种情况,可以考虑将appId切分为appId1、appId2、appId3等,实现类似水平分片的效果。
参考文献
https://github.com/HelloGitHub-Team/Article/tree/master/contents/Java/PowerJob
https://www.yuque.com/powerjob/guidence/intro
欢迎关注公众号【消息中间件】(middleware-mq),更新消息中间件的源码解析和最新动态!
